Модуль 7. Работа с текстовой информацией
Введение
В Windows большинство настроек хранится в реестре, поэтому администраторам так важно знать о том, что такое regedit. А в Linux все находится в папке /etc в виде обычных текстовых файлов, поэтому системным администраторам Linux не обойтись без продвинутых навыков работы с текстовыми файлами.
Из этого модуля вы узнаете о том, как редактировать файлы из командной строки и какие утилиты можно использовать для поиска, замены, слияния и сортировки текста. Мы обсудим, зачем нужны регулярные выражения, и, конечно же, разберемся в конце концов, как выйти из редактора vi/vim без полной перезагрузки компьютера )))
Основные команды для просмотра текстовых файлов
Для просмотра содержания текстовых файлов чаще всего используют следующие утилиты:
cat— объединяет файлы и отправляет данные на стандартный вывод;tac— работает как командаcat, но выводит строки в обратном порядке;less— открывает файл в режиме постраничного просмотра;head— выводит несколько строк с начала файла;tail— выводит несколько строк с конца файла.
Примечание
Напомним, что утилитами называются внешние исполняемые файлы, а командами – встроенные директивы оболочки bash. Для повышения производительности работы некоторые утилиты встраивают внутрь оболочки в виде команд, например, echo. Понять, является ли используемая команда собственно командой или утилитой, вы можете с помощью команды type.
Рассмотрим синтаксис и примеры использования этих команд более подробно.
Утилита cat
Утилита cat объединяет файлы в один поток (от англ. concatenate - объединять, поэтому произносится как «кат», а не «кэт»). Чаще всего утилиту cat используют следующим образом:
сat file1– выводит содержимое файла file1 в стандартный поток вывода, т.е. на экран;cat file1 file2– объединяет содержимое двух файлов file1 и file2 в один поток последовательно друг за другом и выводит на экран;cat -n file1– выводит содержимое файла file1 с автоматической нумерацией строк;cat -s file1– выводит содержимое файла file1, заменяя несколько подряд идущих пустых строк на одну;cat file1 file2 > file3– перенаправляет содержимое файлов file1 и file2 в файл file3.
Однако некоторые продвинутые пользователи используют утилиту cat как простенький редактор для создания небольших текстовых файлов. Если выполнить команду cat > file1, то весь набранный далее текст будет сохранен в указанный файл по нажатию горячих клавиш Ctrl + D. Комбинация Ctrl + C позволяет выйти без сохранения, но предыдущее содержание файла будет потеряно.
Рассмотрим несколько примеров использования:
Проверим настройки DNS, для этого выведем на экран содержимое файла resolv.conf:
localadmin@astra:~$ cat /etc/resolv.conf
# Generated by NetworkManager
nameserver 10.0.2.3
По результату выполнения команды видим, что файл управляется службой NetworkManager.
Выполним объединение двух журналов в один поток, что может быть полезно в дальнейшем, например, для поиска сразу по двум файлам:
localadmin@astra:~$ sudo cat /var/log/boot.log /var/log/kern.log
...
May 10 16:21:27 astra kernel: IPv6: ADDRCONF(NETDEV_CHANGE): eth0: link becomes ready
May 10 18:14:26 astra kernel: e1000: eth0 NIC Link is Down
May 10 18:14:28 astra kernel: e1000: eth0 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: RX
May 10 20:53:13 astra kernel: 17:53:03.546136 timesync vgsvcTimeSyncWorker: Radical host time change: 8 956 796 000 000ns (HostNow=1 716 227 583 546 000 000
May 11 00:00:12 astra kernel: 17:53:13.547092 timesync vgsvcTimeSyncWorker: Radical guest time change: 9 518 866 935 000ns (GuestNow=1 716 227 593 547 082 00
May 11 00:00:12 astra kernel: traps: syslog-ng[467] general protection fault ip:7635a8f7f8a0 sp:7ffed1a22630 error:0 in libpython2.7.so.1.0[7635a8e5c000+17f000]
Перенаправим результат объединения в новый файл:
localadmin@astra:~$ sudo cat /var/log/boot.log /var/log/kern.log > ~/logs
localadmin@astra:~$ cat logs
...
May 10 16:21:27 astra kernel: IPv6: ADDRCONF(NETDEV_CHANGE): eth0: link becomes ready
May 10 18:14:26 astra kernel: e1000: eth0 NIC Link is Down
May 10 18:14:28 astra kernel: e1000: eth0 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: RX
May 10 20:53:13 astra kernel: 17:53:03.546136 timesync vgsvcTimeSyncWorker: Radical host time change: 8 956 796 000 000ns (HostNow=1 716 227 583 546 000 000
May 11 00:00:12 astra kernel: 17:53:13.547092 timesync vgsvcTimeSyncWorker: Radical guest time change: 9 518 866 935 000ns (GuestNow=1 716 227 593 547 082 00
May 11 00:00:12 astra kernel: traps: syslog-ng[467] general protection fault ip:7635a8f7f8a0 sp:7ffed1a22630 error:0 in libpython2.7.so.1.0[7635a8e5c000+17f000]
Результат выполнения будет аналогичен, но строки будут выводиться теперь из файла logs.
Выведем на экран содержимое файла настроек диспетчера службы имен с нумерацией строк:
localadmin@astra:~$ cat -n /etc/nsswitch.conf
...
7 passwd: files
8 group: files
9 shadow: files
10 gshadow: files
...
По результату выполнения команды в строках 7-10 видим, что источниками пользователей, групп и паролей для хоста являются только локальные базы files.
Воспользуемся утилитой cat в качестве текстового редактора, чтобы добавить репозиторий продукта ALD Pro. Для выполнения команды нужно зайти в сессию суперпользователя, т.к. выполнения команды через sudo будет недостаточно. Для выхода из режима редактирования выполните команду Ctrl+C:
root@astra:~# cat > /etc/apt/sources.list.d/aldpro.list
deb https://dl.astralinux.ru/aldpro/frozen/01/2.4.0 1.7_x86-64 main base
^C
После создания файла можете проверить его содержимое так же командой cat, только уже без перенаправления вывода:
root@astra:~# cat /etc/apt/sources.list.d/aldpro.list
deb https://dl.astralinux.ru/aldpro/frozen/01/2.4.0 1.7_x86-64 main base
Примечание
«Редактор» cat, конечно же, суров, но бородатые администраторы используют его еще и в сочетании со специальной конструкцией языка bash, которая задается двумя знаками меньше «<<» и называется «встроенные документы» (от англ. here-document).
Если ввести команду cat > file1 << EOF, то запустится редактор текста, созданный средствами bash, в котором вы сможете вводить текст построчно, а для сохранения результатов нужно будет ввести строку с текстом ограничителя «EOF». В качестве ограничителя может выступать любое сочетание символов, но обычно используют именно эту аббревиатуру, которая является сокращением от фразы «End of File» (с англ. конец файла).
Утилита tac
Команда tac является зеркальным отражением команды cat — она тоже объединяет файлы в один поток, но располагает строки файлов в обратном порядке. Ввиду необходимости изменения порядка строк техническая реализация утилиты немного отличается: сначала tac вычитывает все строки файла, затем отправляет их в поток вывода в обратном порядке. Чаще всего утилиту tac используют следующим образом:
tac file1 file2– выводит строки файла file1 в обратном порядке, затем строки файла file2 также в обратном порядке.
Рассмотрим пример использования:
В работе с журналами может быть полезным инвертировать порядок строк, что можно сделать как раз с помощью утилиты tac:
localadmin@astra:~$ sudo tac /var/log/boot.log /var/log/kern.log
May 6 15:46:46 astra kernel: AMD AuthenticAMD
May 6 15:46:46 astra kernel: Intel GenuineIntel
May 6 15:46:46 astra kernel: KERNEL supported cpus:
May 6 15:46:46 astra kernel: Command line: BOOT_IMAGE=/boot/vmlinuz-5.15.0-70-generic root=UUID=33f4245d-33e8-48a1-9be7-0841215e1f46 ro parsec.max_ilev=63 quiet net.ifnames=0
May 16 15:46:46 astra kernel: Linux version 5.15.0-70-generic (builder@build5) (gcc (AstraLinuxSE 8.3.0-6) 8.3.0, GNU ld (GNU Binutils for AstraLinux) 2.31.1) #astra2 SMP Mon Apr 10 13:35:08 UTC 2023 (Astra 5.15.0-70.astra2-generic 5.15.92)
В результате выполнения команды в конце вывода мы увидим строки из начала файла
Утилита less
Утилита less (от англ. меньше) реализует функции программы для просмотра текстов. Она дает возможность листать многостраничные файлы и выполнять по ним поиск. Приемы работы с интерфейсом утилиты less были подробно рассмотрены в модуле 5 «Работа со справочными системами», поэтому не будем на этом останавливаться.
Чаще всего утилита вызывается таким образом:
less file1– просмотр файла file1 утилитойless;cat file | less– вывод содержимого файла file1 в стандартный поток передачи его по конвейеру утилитеless.
Утилита head
Утилита head выводит n первых строк файла (англ. head - заголовок). По умолчанию 10 строк.
head file– выводит первые 10 строк файла file на экран;head -n 3 file– выводит первые 3 строки файла file на экран.
Примеры использования:
Вывод первых 10 строк файла /etc/passwd
localadmin@astra:~$ head /etc/passwd
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/usr/sbin/nologin
man:x:6:12:man:/var/cache/man:/usr/sbin/nologin
lp:x:7:7:lp:/var/spool/lpd:/usr/sbin/nologin
mail:x:8:8:mail:/var/mail:/usr/sbin/nologin
news:x:9:9:news:/var/spool/news:/usr/sbin/nologin
Вывод первых 3 строк файла /etc/passwd
localadmin@astra:~$ head -n 3 /etc/passwd
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
Утилита tail
Утилита tail выводит n последних строк файла (англ. tail - хвост). По умолчанию 10 строк. Утилита может продолжать показывать новые строки по мере их добавления к файлу.
tail file– выводит последние 10 строк файла file в стандартный поток вывода, т.е. на экран;tail -n 3 file– выводит последние 3 строки файла file на экран;tail -f -n 3 file– выводит последние 3 строки файла file на экран и продолжает свою работу, отображая новые строки, добавляемые к этому файлу. Для завершения работы утилиты нужно использовать горячее сочетание клавиш Ctrl + C.
Примеры использования:
Вывод последних 10 строк файла /etc/passwd:
localadmin@astra:~$ tail /etc/passwd
fly-dm:x:107:118::/var/lib/fly-dm:/usr/sbin/nologin
ntp:x:108:121::/nonexistent:/usr/sbin/nologin
Debian-exim:x:109:122::/var/spool/exim4:/usr/sbin/nologin
nm-openvpn:x:110:124:NetworkManager OpenVPN,,,:/var/lib/openvpn/chroot:/usr/sbin/nologin
hplip:x:111:7:HPLIP system user,,,:/run/hplip:/bin/false
logcheck:x:112:125:logcheck system account,,,:/var/lib/logcheck:/usr/sbin/nologin
avahi:x:113:126:Avahi mDNS daemon,,,:/var/run/avahi-daemon:/usr/sbin/nologin
localadmin:x:1000:1000:localadmin,,,:/home/localadmin:/bin/bash
systemd-coredump:x:999:999:systemd Core Dumper:/:/usr/sbin/nologin
vboxadd:x:998:1::/var/run/vboxadd:/bin/false
Вывод последних 3 строк файла /etc/passwd:
localadmin@astra:~$ tail -n 3 /etc/passwd
localadmin:x:1000:1000:localadmin,,,:/home/localadmin:/bin/bash
systemd-coredump:x:999:999:systemd Core Dumper:/:/usr/sbin/nologin
vboxadd:x:998:1::/var/run/vboxadd:/bin/false
Вывод последних 3 строк файла /var/log/auth.log и новых строк в интерактивном режиме:
localadmin@astra:~$ sudo tail -f -n 3 /var/log/auth.log
[sudo] пароль для localadmin:
Jun 14 10:30:01 astra CRON[2096]: pam_unix(cron:session): session opened for user root by (uid=0)
Jun 14 10:30:01 astra CRON[2096]: pam_unix(cron:session): session closed for user root
Jun 14 10:53:42 astra sudo[2173]: pam_unix(sudo:auth): authentication failure; logname=localadmin uid=
1000 euid=0 tty=/dev/pts/0 ruser=localadmin rhost= user=localadmin
Jun 14 10:53:49 astra sudo[2173]: localadmin : TTY=pts/0 ; PWD=/home/localadmin ; USER=root ; COMMAND=
/usr/bin/tail -f -n 3 /var/log/auth.log
Jun 14 10:53:49 astra sudo[2173]: pam_kiosk2(sudo:session): need_continue: UID 0 detected, skipping. U
ser: root
Jun 14 10:53:49 astra sudo[2173]: pam_unix(sudo:session): session opened for user root by localadmin(u
id=0)
^C
Примечание
Для выхода из интерактивного режима используйте Ctrl + C, о чем сообщает «^C» на последней строке.
Основные команды для редактирования текстов из командной строки
Рассмотрим еще несколько часто используемых команд:
wc [file]— выводит на экран статистику по количеству строк, слов и байт в указанном файле;nl [file]— добавляет нумерацию строк и выводит на экран текст из указанного файла. Пустые строки не нумеруются;tee file— перенаправляет входной поток одновременно и в файл file, и в стандартный поток вывода. Утилита может перенаправлять поток сразу в несколько файлов;sort— выполняет сортировку строк;uniq— выполняет удаление повторяющихся строк;cut— вырезает фрагмент из каждой строки файла и выводит результаты в стандартный поток вывода, с помощью чего можно вывести данные в табличном виде;tr— заменяет подстроку и передает поток дальше;xargs— выполняет указанную команду, дополняя ее аргументы информацией из строк, которые она получает из стандартного ввода. Команда может быть выполнена несколько раз по количеству строк, которые будут направлены ей.
Рассмотрим синтаксис и примеры использования этих команд более подробно.
Утилита wc
Анализирует содержимое файла и отправляет в стандартный поток вывода статистику по количеству строк, слов и байт (от англ. word count – количество слов).
wc file– выведет на экран количество строк, слов и байт в файле file;wc -l file– выведет на экран количество строк в файле file;wc -w file– выведет на экран количество слов в файле file;wc -m file– выведет на экран количество символов в файле file;wc -c file– выведет на экран количество байт в файле file;wc -l file1 file2 file3– выведет на экран количество строк в каждом из файлов file1, file2 и file3;ls | wc -l– выведет на экран количество файлов и каталогов в текущей директории, за исключением скрытых объектов. Файлы и директории в Linux считаются скрытыми (hidden), если их название начинается с точки «.»;ls -A | wc -l– выведет на экран количество всех файлов и каталогов в текущей директории, за исключением скрытых объектов;ps -e | wc -l– выведет на экран количество процессов в системе. Реальное число процессов меньше на один (командаwcсчитает все строки, в том числе и заголовок таблицы).
Примеры использования:
Выведет на экран количество строк, слов и байт в файле .bashrc:
localadmin@astra:~$ cd
localadmin@astra:~$ wc .bashrc
113 483 3526 .bashrc
Выведет на экран количество строк в файле .bash_history:
localadmin@astra:~$ wc -l .bash_history
113 .bash_history
Выведет на экран количество файлов и каталогов в текущей директории, за исключением скрытых:
localadmin@astra:~$ ls | wc -l
27
Выведет на экран количество всех файлов и каталогов в текущей директории, за исключением скрытых:
localadmin@astra:~$ ls -A | wc -l
48
Выведет на экран количество процессов в системе. Реальное число процессов меньше на один (команда wc считает все строки, в том числе и заголовок таблицы):
localadmin@astra:~$ ps -e | wc -l
151
Утилита nl
Добавляет в выходной поток нумерацию строк (от англ. number lines – нумерация строк).
nl file– выведет на экран файл file, добавив нумерацию строк с выравниванием нумерации по правому краю.nl -n ln file– выведет на экран файл file, добавив нумерацию строк с выравниванием нумерации по левому краю.
Примеры использования:
Выведет на экран файл file, добавив нумерацию строк с выравниванием нумерации по правому краю.
localadmin@astra:~$ nl /etc/passwd
1 root:x:0:0:root:/root:/bin/bash
2 daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
3 bin:x:2:2:bin:/bin:/usr/sbin/nologin
4 sys:x:3:3:sys:/dev:/usr/sbin/nologin
5 sync:x:4:65534:sync:/bin:/bin/sync
…
30 hplip:x:111:7:HPLIP system user,,,:/run/hplip:/bin/false
31 logcheck:x:112:125:logcheck system account,,,:/var/lib/logcheck:/usr/sbin/nologin
32 avahi:x:113:126:Avahi mDNS daemon,,,:/var/run/avahi-daemon:/usr/sbin/nologin
33 localadmin:x:1000:1000:localadmin,,,:/home/localadmin:/bin/bash
34 systemd-coredump:x:999:999:systemd Core Dumper:/:/usr/sbin/nologin
35 vboxadd:x:998:1::/var/run/vboxadd:/bin/false
Выведет на экран файл file, добавив нумерацию строк с выравниванием нумерации по левому краю
localadmin@astra:~$ nl -n ln /etc/passwd
1 root:x:0:0:root:/root:/bin/bash
2 daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
3 bin:x:2:2:bin:/bin:/usr/sbin/nologin
4 sys:x:3:3:sys:/dev:/usr/sbin/nologin
5 sync:x:4:65534:sync:/bin:/bin/sync
…
30 hplip:x:111:7:HPLIP system user,,,:/run/hplip:/bin/false
31 logcheck:x:112:125:logcheck system account,,,:/var/lib/logcheck:/usr/sbin/nologin
32 avahi:x:113:126:Avahi mDNS daemon,,,:/var/run/avahi-daemon:/usr/sbin/nologin
33 localadmin:x:1000:1000:localadmin,,,:/home/localadmin:/bin/bash
34 systemd-coredump:x:999:999:systemd Core Dumper:/:/usr/sbin/nologin
35 vboxadd:x:998:1::/var/run/vboxadd:/bin/false
Утилита tee
Утилита перенаправляет входной поток одновременно и в указанные файлы, и в стандартный поток вывода. Используется следующим образом:
<command> | tee file1 file2– результат командыcommandбудет выведен на экран и записан в файлы file1 и file2;<command> <directory> -h -d1 | tee file | nl– результат выполнения командыcommandбудет записан в файл «как есть», а на экран будет выведен с нумерацией строк.
Примеры использования:
Результат команды command будет выведен на экран и записан в файлы file1 и file2:
localadmin@astra:~$ date | tee file1 file2
Пт июн 16 08:47:28 MSK 2023
localadmin@astra:~$ cat file1
Пт июн 16 08:47:28 MSK 2023
localadmin@astra:~$ cat file2
Пт июн 16 08:47:28 MSK 2023
Результат выполнения команды du будет записан в файл «как есть», а на экран будет выведен с нумерацией строк:
localadmin@astra:~$ du /usr -h -d1 | tee du.out | nl
1 4,0K /usr/libx32
2 4,0K /usr/games
3 4,0K /usr/lib64
4 4,1G /usr/lib
5 4,0K /usr/lib32
6 76K /usr/local
7 342M /usr/bin
8 1,2M /usr/libexec
9 33M /usr/sbin
10 12M /usr/include
11 189M /usr/src
12 2,0G /usr/share
13 8,0K /usr/etc
14 6,6G /usr
localadmin@astra:~$ cat du.out
4,0K /usr/libx32
4,0K /usr/games
4,0K /usr/lib64
4,1G /usr/lib
4,0K /usr/lib32
76K /usr/local
342M /usr/bin
1,2M /usr/libexec
33M /usr/sbin
12M /usr/include
189M /usr/src
2,0G /usr/share
8,0K /usr/etc
6,6G /usr
Утилита sort
Сортирует строки текстовых файлов. Сортировка идет в следующем порядке:
строки с цифрами размещаются выше других строк;
строки, начинающиеся с букв нижнего регистра, размещаются выше;
сортировка выполняется в соответствии с алфавитом;
строки сортируются сначала по алфавиту, а уже вторично по другим правилам.
Утилита используется следующим образом:
sort file– выведет на экран отсортированный файл file.command | sort -r– сортировка вывода командыcommandв обратном порядке (-r).sort -u file– выведет на экран отсортированный файл file и удалит из вывода дубликаты строк.sort –k 3 file– выведет на экран содержимое файла file с разделением на столбцы (используя пробел в качестве символа-разделителя) и сортировкой по третьему столбцу (-k 3).sort –k1,1 -k3,3 file– выведет на экран содержимое файла file с разделением на столбцы и сортировкой по 1 и 3 столбцам (-k 1,1 -k3,3). Ключ (-k1,1) означает сортировать только по первому столбцу, т.е. начать с первого столбца и закончить на первом же столбце. При указании ключа в виде (-k1), сортировка будет сделана по всем столбцам, начиная с первого, соответственно, сортировка по третьему столбцу может не сработать.cat /etc/passwd | sort -t: -k 3 -nr | head– выведет первые 10 строк (head) результата сортировки файла /etc/passwd по 3 столбцу (-k 1) с разделителем столбцов «:» (-t:) в обратном порядке (-r) при числовой сортировке (-n).
Примеры использования:
Создадим 2 тестовых файла для демонстрации команды sort:
localadmin@astra:~$ echo -e "computer\nmouse\nLAPTOP\ndata\nAstraLinux\nlaptop\nLinux\nlaptop" > test_sort1.txt
localadmin@astra:~$ echo -e "a c b d\nd b a c\nc a d b\nb da fg r\nc e s we\nc ds a ck" > test_sort2.txt
Команда echo с ключом –e интерпретирует специальные символы, в данном случае n – символ новой строки:
localadmin@astra:~$ cat test_sort1.txt
computer
mouse
LAPTOP
data
AstraLinux
laptop
Linux
laptop
Отсортируем файл test_sort1.txt:
localadmin@astra:~$ sort test_sort1.txt
AstraLinux
computer
data
laptop
laptop
LAPTOP
Linux
mouse
Отсортируем файл test_sort1.txt в обратном порядке:
localadmin@astra:~$ sort -r test_sort1.txt
mouse
Linux
LAPTOP
laptop
laptop
data
computer
AstraLinux
Отсортируем файл test_sort1.txt и уберем из вывода дубликаты:
localadmin@astra:~$ sort -u test_sort1.txt
AstraLinux
computer
data
laptop
LAPTOP
Linux
mouse
Отсортируем файл по 2 столбцу (разделитель по умолчанию пробел):
localadmin@astra:~$ cat test_sort2.txt
a c b d
d b a c
c a d b
b da fg r
c e s we
c ds a ck
localadmin@astra:~$ cat test_sort2.txt | sort -k 2
c a d b
d b a c
a c b d
b da fg r
c ds a ck
c e s we
Отсортируем файл по 1 и 3 столбцам (по значению c в колонке 1 видно, что работает и сортировка по колонке 3):
localadmin@astra:~$ cat test_sort2.txt | sort -k1,1 -k3,3
a c b d
b da fg r
c ds a ck
c a d b
c e s we
d b a c
Выведем первые 10 строк результата сортировки файла /etc/passwd по 3 столбцу (-k 3) с разделителем столбцов: (-t:) в обратном порядке (-r) при числовой сортировке (-n):
localadmin@astra:~$ cat /etc/passwd | sort -t: -k 3 -nr | head
nobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologin
localadmin:x:1000:1000:localadmin,,,:/home/localadmin:/bin/bash
systemd-coredump:x:999:999:systemd Core Dumper:/:/usr/sbin/nologin
vboxadd:x:998:1::/var/run/vboxadd:/bin/false
avahi:x:113:126:Avahi mDNS daemon,,,:/var/run/avahi-daemon:/usr/sbin/nologin
logcheck:x:112:125:logcheck system account,,,:/var/lib/logcheck:/usr/sbin/nologin
hplip:x:111:7:HPLIP system user,,,:/run/hplip:/bin/false
nm-openvpn:x:110:124:NetworkManager OpenVPN,,,:/var/lib/openvpn/chroot:/usr/sbin/nologin
Debian-exim:x:109:122::/var/spool/exim4:/usr/sbin/nologin
ntp:x:108:121::/nonexistent:/usr/sbin/nologin
Утилита uniq
Утилита позволяет найти или удалить повторяющиеся строки. Для правильной фильтрации список должен быть предварительно отсортирован. Следует иметь в виду, что результат команды может отличаться от ожидаемого, например, ключ -i, который позволяет игнорировать регистр при сравнении, не работает с кириллицей.
command | sort | uniq– результат командыcommandбудет отсортирован, и все строки будут выведены на экран без повторов.uniq -d– выводит только строки, у которых есть повторы. Из каждого набора повторяющихся строк будет выведена только одна.uniq -u– выводит только строки, у которых нет повторов.uniq -с– выводит уникальные и неуникальные строки с указанием того, сколько раз эти строки присутствовали в исходном тексте (см. число в начале строки).uniq -i– не учитывает регистр при сравнении строк. Не работает с кириллицей.
Примеры использования:
Создание для демонстрации двух файлов с набором символов, в том числе повторяющихся:
localadmin@astra:~$ echo -e "а\nб\nв\nА\nг\nв\nд\nв\nД" > test_ru_uniq.txt
localadmin@astra:~$ echo -e "a\nb\nc\nA\nb\nd\nc\ne\nC" > test_en_uniq.txt
Первый файл с символами кириллицы. Фильтрация командой uniq не работает с неотсортированным списком:
localadmin@astra:~$ cat test_ru_uniq.txt | uniq
а
б
в
А
г
в
д
в
Д
Вывод всех уникальных строк:
localadmin@astra:~$ cat test_ru_uniq.txt | sort | uniq
а
А
б
в
г
д
Д
Вывод только тех строк, у которых нет повторов.
localadmin@astra:~$ cat test_ru_uniq.txt | sort | uniq -u
а
А
б
г
д
Д
Вывод только тех строк, у которых есть повторы. Из каждого набора повторяющихся строк будет выведена только одна:
localadmin@astra:~$ cat test_ru_uniq.txt | sort | uniq -d
в
Вывод только уникальных строк, не учитывая регистр (не работает с кириллицей):
localadmin@astra:~$ cat test_ru_uniq.txt | sort | uniq -i
а
А
б
в
г
д
Д
Второй файл с символами латиницы. Фильтрация командой uniq не работает с неотсортированным списком:
localadmin@astra:~$ cat test_en_uniq.txt | sort | uniq
a
A
b
c
C
d
e
Вывод только уникальных строк, не учитывая регистр:
localadmin@astra:~$ cat test_en_uniq.txt | sort | uniq -i
a
b
c
d
e
Вывод всех уникальных строк и количества повторов (цифра в начале строки):
localadmin@astra:~$ cat test_en_uniq.txt | sort | uniq -c
1 a
1 A
2 b
2 c
1 C
1 d
1 e
Вывод всех уникальных строк и количества повторов (цифра в начале строки), без учета регистра:
localadmin@astra:~$ cat test_en_uniq.txt | sort | uniq -ic
2 a
2 b
3 c
1 d
1 e
Вывод количества строк в файле /var/log/user.log:
localadmin@astra:~$ sudo cat /var/log/user.log | sort | wc -l
17
Вывод количества уникальных строк в файле /var/log/user.log:
localadmin@astra:~$ sudo cat /var/log/user.log | sort | uniq | wc -l
10
Вывод строк в файле /var/log/user.log, у которых нет повторов:
localadmin@astra:~$ sudo cat /var/log/user.log | sort | uniq -u
Jun 15 09:24:44 astra vboxadd-service.sh[1008]: Starting VirtualBox Guest Addition service.
Jun 15 09:24:44 astra vboxadd-service.sh[1021]: VirtualBox Guest Addition service started.
Jun 15 09:33:55 astra pulseaudio[1638]: [alsa-source-Intel ICH] alsa-source.c: ALSA woke us up to read new data from the device, but there was actu
ally nothing to read.
Jun 15 09:33:55 astra pulseaudio[1638]: [alsa-source-Intel ICH] alsa-source.c: Most likely this is a bug in the ALSA driver 'snd_intel8x0'. Please
report this issue to the ALSA developers.
Jun 15 09:33:55 astra pulseaudio[1638]: [alsa-source-Intel ICH] alsa-source.c: We were woken up with POLLIN set -- however a subsequent snd_pcm_ava
il() returned 0 or another value < min_avail.
Jun 15 09:33:55 astra pulseaudio[1680]: [pulseaudio] pid.c: Daemon already running.
Вывод только повторяющихся строк в файле /var/log/user.log:
localadmin@astra:~$ sudo cat /var/log/user.log | sort | uniq -D
Jun 15 09:33:54 astra pulseaudio[1638]: [pulseaudio] alsa-util.c: Disabling timer-based scheduling because running inside a VM.
Jun 15 09:33:54 astra pulseaudio[1638]: [pulseaudio] alsa-util.c: Disabling timer-based scheduling because running inside a VM.
Jun 15 09:33:55 astra org.kde.powerdevil.backlighthelper[1706]: QDBusArgument: read from a write-only object
Jun 15 09:33:55 astra org.kde.powerdevil.backlighthelper[1706]: QDBusArgument: read from a write-only object
Jun 15 09:33:55 astra org.kde.powerdevil.backlighthelper[1706]: QDBusArgument: read from a write-only object
Jun 15 09:33:55 astra org.kde.powerdevil.chargethresholdhelper[1693]: QDBusArgument: read from a write-only object
Jun 15 09:33:55 astra org.kde.powerdevil.chargethresholdhelper[1693]: QDBusArgument: read from a write-only object
Jun 15 09:33:55 astra org.kde.powerdevil.chargethresholdhelper[1693]: QDBusArgument: read from a write-only object
Jun 15 09:33:55 astra org.kde.powerdevil.discretegpuhelper[1673]: QDBusArgument: read from a write-only object
Jun 15 09:33:55 astra org.kde.powerdevil.discretegpuhelper[1673]: QDBusArgument: read from a write-only object
Jun 15 09:33:55 astra org.kde.powerdevil.discretegpuhelper[1673]: QDBusArgument: read from a write-only object
Вывод только повторяющихся строк в файле /var/log/user.log, где из каждого набора повторяющихся строк будет выведена только одна:
localadmin@astra:~$ sudo cat /var/log/user.log | sort | uniq -d
Jun 15 09:33:54 astra pulseaudio[1638]: [pulseaudio] alsa-util.c: Disabling timer-based scheduling because running inside a VM.
Jun 15 09:33:55 astra org.kde.powerdevil.backlighthelper[1706]: QDBusArgument: read from a write-only object
Jun 15 09:33:55 astra org.kde.powerdevil.chargethresholdhelper[1693]: QDBusArgument: read from a write-only object
Jun 15 09:33:55 astra org.kde.powerdevil.discretegpuhelper[1673]: QDBusArgument: read from a write-only object
Утилита cut
Утилита вырезает фрагмент из каждой строки файла и выводит результаты в стандартный поток вывода, с помощью чего можно вывести данные в табличном виде. Пример использования:
cut -c 2,3,5 file– выведет на экран текст из файла file построчно и только 2, 3 и 5 символы в каждой из строк;cut -c 3-6 file– выведет на экран текст из файла file построчно и только символы с 3 по 6 в каждой из строк;cut -c -5 file– выведет на экран текст из файла file построчно и только первые 5 символов в каждой из строк;cut -c 3- file– выведет на экран текст из файла file построчно и только символы с 3 до последнего в каждой из строк;cut -d : -f 1,3 file– выведет на экран текст из файла file построчно и только первый и 3 столбцы. Строки разделены на столбцы разделителем «:».
Примеры использования:
Выводит на экран список всех пользователей в текущей системе:
localadmin@astra:~$ cut -d : -f 1 /etc/passwd
root
daemon
bin
sys
sync
games
man
lp
mail
...
Выводит список пользователей, авторизованных в текущей системе:
localadmin@astra:~$ who | cut -d' ' -f1 | sort
localadmin
localadmin
Выводит имя службы, использующей порт 80:
localadmin@astra:~$ grep -w 80 /etc/services | cut -f 1 | uniq
http
Выводит тип CPU:
localadmin@astra:~$ cat /proc/cpuinfo | grep "name" | cut -d : -f2 | uniq
Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz
Утилита tr
Выполняет преобразование, подстановку (замену), сокращение и/или удаление символов, поступающих из стандартного входного потока, записывая результат на стандартное устройство вывода.
tr строка1 строка2 < file– выведет на экран содержимое файла file, заменив в нем символы из строка1 на символы из строка2;tr -c строка1 строка2 < file1 > file2– сохранит в файле file2 содержимое файла file1, заменив в нем символы, отсутствующие в строка1, на символы из строка2;<command> | tr -d строка1– выведет на экран результат команды<command>, удалив из него символы, встречающиеся в строка1;<command> | tr -s строка1 строка2– выведет на экран результат команды<command>, заменив в нем последовательность символов из строка1;<command> | tr -сs строка1 строка2– выведет на экран результат команды<command>, заменив в нем символы из строка1 на символы из строка2 и сжав последовательности символов из строка2 (удалив дубликаты символов).
Примеры использования:
Выведет на экран текст в верхнем регистре:
localadmin@astra:~$ echo "text" | tr '[:lower:]' '[:upper:]'
TEXT
localadmin@astra:~$ echo "text" | tr 'a-z' 'A-Z'
TEXT
Выведет на экран только цифры из текста:
localadmin@astra:~$ echo "номер телефона 8-960-999-99-99" | tr -cd [:digit:]
89609999999
Выведет на экран текст, заменив каждую из последовательностей буквы r на одну букву:
localadmin@astra:~$ echo "Astrrrrra" | tr -s 'r'
Astra
Выведет на экран только буквы и цифры в тексте, а все другие символы заменит на символ новой строки:
localadmin@astra:~$ echo 'first second third' | tr -cs '[:alnum:]' '\n'
first
second
third
Выведет на экран текст, удалив из него все цифры:
localadmin@astra:~$ echo "1 пожалуйста 2 удалите 3 все 4 цифры" | tr -d [:digit:]
пожалуйста удалите все цифры
Выведет на экран содержимое переменной PATH построчно, заменив разделитель „:“ на символ новой строки:
localadmin@astra:~$ echo $PATH | tr ':' '\n'
/usr/local/bin
/usr/bin
/bin
/usr/local/games
/usr/games
Утилита xargs
Выполнение команд с использованием данных, поступающих из стандартного потока ввода. Обычно используется в сочетании с другими командами через конвейер.
echo "file1 file2 file3" | xargs touch– для каждого аргумента со стандартного ввода (file1, file2 и file3) будет выполнена командаtouchи будут созданы (если их нет) 3 файла. Командаtouch file1 file2 file3выполнит то же самое;echo "file1 file2 file3" | xargs -t touch– сделает то же самое, но выведет на экран команду перед её выполнением;echo "file1 file2 file3" | xargs -p touch– перед выполнением команды будет запрошено подтверждение у пользователя. Для подтверждения необходимо ввести «y»;echo "file1 file2 file3" | xargs -n 1 -t touch– ключ-nограничивает количество аргументов, передающихся команде. В данном случае будут выполнены 3 командыtouchс одним аргументом в каждой команде вместо одной командыtouchс тремя аргументами;echo "file1;file2;file3" | xargs -d \; -t touch– ключ-dпозволяет указать разделитель (отдельный символ или escape-последовательность) и разбить текст на отдельные аргументы;xargs -t -L 1 -a ips.txt ping -c 1– ключ-aпозволяет указать файл, который будет использоваться вместо стандартного ввода. А ключ-Lпозволяет указать количество строк, считываемых из файла за один раз, перед передачей их команде на выполнение в качестве аргумента.find ~/test* -type f -print0 | xargs -0 rm -f– ключ print0 в командеfindуказывает ей, что необходимо вывести полный путь до найденного файла и вместо символа новой строки использовать символ null для правильной интерпретации файлов, у которых есть в именах символы новой строки или другие пробельные символы. Ключ «0» в командеxargsпозволяет правильно интерпретировать такой вывод командыfind.echo "file1 file2 file3" | xargs -t -I % sh -c '{ touch %; ls -l %; }'– ключ-Iпозволяет указать символ или строку, каждое вхождение которой в команде будет заменено на аргументы. Это используется для запуска нескольких команд (в данном случаеtouchиls– сначала файлы будут созданы, а затем информация о них будет считана и выведена на экран), которые выполняются последовательно одна за другой.echo 192.168.1.{1..254} | tr " " : | xargs -d : -L 1 -P 100 ping -c 1– ключ-Pпозволяет распараллелить выполнение команды. Цифра указывает максимальное количество процессов, которые будут выполняться одновременно. В этом примере можно «пропинговать» все адреса хостов в сети за 3 итерации. Другой пример: параллельная загрузка файлов из интернета с помощью конвейера из командwgetиxargs.
Примеры использования:
Для каждого аргумента со стандартного ввода (file1, file2 и file3) будет выполнена команда touch и будут созданы (если их нет) 3 файла:
localadmin@astra:~$ echo "file1 file2 file3" | xargs touch
localadmin@astra:~$ ls file{1..3}
file1 file2 file3
Сделает то же самое, но выведет команду перед её выполнением:
localadmin@astra:~$ echo "file1 file2 file3" | xargs -t touch
touch file1 file2 file3
Запросит подтверждение пользователя перед выполнением:
localadmin@astra:~$ echo "file1 file2 file3" | xargs -p touch
touch file1 file2 file3 ?...y
Ключ -n ограничивает количество аргументов, передающихся команде:
localadmin@astra:~$ echo "file1 file2 file3" | xargs -n 1 -t touch
touch file1
touch file2
touch file3
В данном случае будут выполнены 3 команды touch с одним аргументом в каждой, вместо одной команды touch с тремя аргументами
Ключ -d позволяет выбрать разделитель для деления текста, поступающего на вход команде на отдельные аргументы:
localadmin@astra:~$ echo "file1;file2;file3" | xargs -d \; touch
Входной текст можно передавать не только из стандартного ввода, но и читать из файла. Ключ -L позволяет указать, сколько строк текста будут обрабатываться как один аргумент:
localadmin@astra:~$ echo -e "77.88.8.8\n77.88.8.1" > ips.txt
localadmin@astra:~$ cat ips.txt
77.88.8.8
77.88.8.1
localadmin@astra:~$ xargs -t -L 1 -a ips.txt ping -c 1
ping -c 1 77.88.8.8
PING 77.88.8.8 (77.88.8.8) 56(84) bytes of data.
64 bytes from 77.88.8.8: icmp_seq=1 ttl=246 time=36.2 ms
--- 77.88.8.8 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 36.214/36.214/36.214/0.000 ms
ping -c 1 77.88.8.1
PING 77.88.8.1 (77.88.8.1) 56(84) bytes of data.
64 bytes from 77.88.8.1: icmp_seq=1 ttl=52 time=50.7 ms
--- 77.88.8.1 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 50.739/50.739/50.739/0.000 ms
Ключ -print0 в команде find указывает ей, что необходимо вывести полный путь до найденного файла и вместо символа новой строки использовать символ null для правильной интерпретации файлов, у которых есть в именах символы новой строки или другие пробельные символы. Ключ -0 в команде xargs позволяет правильно интерпретировать такой вывод команды find:
localadmin@astra:~$ find ~/test* -type f -print0 | xargs -0 rm -f
Ключ -I позволяет указать символ или строку, каждое вхождение которой в команде будет заменено на аргументы. Это используется для запуска нескольких команд (в данном случае touch и ls – сначала файлы будут созданы, а затем информация о них будет считана и выведена на экран), которые выполняются последовательно одна за другой:
localadmin@astra:~$ echo "file1 file2 file3" | xargs -t -I % sh -c '{ touch %; ls -l %; }'
sh -c { touch file1 file2 file3; ls -l file1 file2 file3; }
-rw-r--r-- 1 localadmin localadmin 0 июн 21 10:21 file1
-rw-r--r-- 1 localadmin localadmin 0 июн 21 10:21 file2
-rw-r--r-- 1 localadmin localadmin 0 июн 21 10:21 file3
Ключ -P позволяет распараллелить выполнение команды, цифра указывает максимальное количество процессов, которые будут выполняться одновременно. В этом примере можно пропинговать все адреса хостов в сети за 3 итерации:
echo 192.168.1.{1..254} | tr " " : | xargs -d : -L 1 -P 100 ping -c 1
Утилиты grep, sed и awk и регулярные выражения
В этом разделе представлены три дополнительных инструмента для работы с текстом:
grep– утилита для поиска строк по шаблону;sed– кроме поиска, утилита позволяет преобразовывать текст, например, выполнять вставку или замену фрагментов текста;awk– самый мощный инструмент в представленном списке. Это целый язык сценариев для обработки и фильтрации текста, предлагающий множество функций, которых нет в первых двух утилитах.
Примечание
Есть еще кое-что общее между этими тремя утилитами. Все они умеют работать с регулярными выражениями. Более того, использование регулярных выражений очень существенно расширяет их возможности. Подробное изучение регулярных выражений не является темой этого курса, однако будут рассмотрены базовые приемы работы с ними.
Далее рассмотрим каждую из них подробнее.
Утилита grep
Название команды grep расшифровывается как «search globally for lines matching the regular expression, and print them» (глобальный поиск строк по регулярному выражению и их вывод).
Команда grep предоставляет много возможностей для фильтрации текста: выбрать нужные строки из текстовых файлов, отфильтровать вывод команд и искать файлы в файловой системе, которые содержат определенные строки. Эта утилита очень популярна, поэтому предустановлена почти во всех дистрибутивах.
Два основных синтаксиса использования команды grep:
grep [<опции>] <шаблон> [/путь/к/файлу/или/папке...]<команда> | grep [<опции>] <шаблон>
Где:
Опции — это дополнительные параметры, с помощью которых указываются различные настройки поиска и вывода, например, количество строк или режим инверсии.
Шаблон — это любая строка или регулярное выражение, по которому будет выполняться поиск.
Имя файла или папки — это то место, где будет выполняться поиск.
Grepпозволяет искать в нескольких файлах и даже в каталоге, используя рекурсивный режим.
Основные опции утилиты grep:
-E(--extended-regexp) - включить расширенный режим регулярных выражений (ERE);-F(--fixed-strings) - рассматривать шаблон поиска как обычную строку, а не регулярное выражение;-G(--basic-regexp) - интерпретировать шаблон поиска как базовое регулярное выражение (BRE);-P(--perl-regexp) - рассматривать шаблон поиска как регулярное выражение Perl;-e(--regexp) - альтернативный способ указать шаблон поиска. Опцию можно использовать несколько раз, что позволяет указать несколько шаблонов для поиска файлов, содержащих один из них;-f(--file) - читать шаблон поиска из файла;-i(--ignore-case) - не учитывать регистр символов;-v(--invert-match) - вывести только те строки, в которых шаблон поиска не найден;-w(--word-regexp) - искать шаблон как слово, отделенное пробелами или другими знаками препинания;-x(--line-regexp) - искать шаблон как целую строку от начала и до символа перевода строки;-c- вывести количество найденных строк;--color- включить цветной режим, доступные значения: never, always и auto;-L(--files-without-match) - выводить только имена файлов. Будут выведены все файлы, в которых выполняется поиск;-l(--files-with-match) - аналогично предыдущему, но будут выведены только файлы, в которых есть хотя бы одно вхождение;-m(--max-count) - остановить поиск, после того как будет найдено указанное количество строк;-o(--only-matching) - отображать только совпавшую часть вместо отображения всей строки;-h(--no-filename) - не выводить имя файла;-q(--quiet) - не выводить ничего;-s(--no-messages) - не выводить ошибки чтения файлов;-A(--after-content) - показать вхождение и n строк после него;-B(--before-content) - показать вхождение и n строк до него;-C- показать n строк до и после вхождения;-a(--text) - обрабатывать двоичные файлы как текст;--exclude- пропустить файлы, имена которых соответствуют регулярному выражению;--exclude-dir- пропустить все файлы в указанной директории;-I- пропускать двоичные файлы;--include- искать только в файлах, имена которых соответствуют регулярному выражению;-r- рекурсивный поиск по всем подпапкам;-R- рекурсивный поиск, включая ссылки.
Примеры использования:
grep string file– выведет на экран строки из файла file, содержащие вхождения строки string.grep -i string file– опция -i позволяет игнорировать регистр при поиcке вхождений. String, STRING, string будут эквиваленты при поиске.grep -e string1 -e string2 file– опция -e позволяет задать несколько условий для поиска.grep -n string file– опция -n позволяет выводить номера строк, в которых были найдены вхождения.grep -F “special symbol” file– опция -F позволяет явно указать утилите, что строка является строкой, а не регулярным выражением. В противном случае при использовании специальных символов (если регулярное выражение записано неверно) команда выдаст соответствующую ошибку.command | grep string– фильтрация вывода команды – выведет на экран все строки из вывода командыcommand, содержащие строку string.grep -A4 string fileзадать количество строк (в данном случае 4), которое будет выведено на экран, после строки с найденным вхождением. Полезно для понимания контекста, например, при поиске ошибок в логах. Опции -B и -C похожи по функционалу: -B – выводит заданное количество строк до строки с вхождением (например, -B3), а -С – строки как до, так и после строки с вхождением (например, -С2).grep -r string directory– опция -r позволяет вести поиск файлов не только в указанном каталоге, но и рекурсивно - во всех его подкаталогах.grep -rl string directory– опция -I (заглавная i) позволяет исключить из результатов поиска двоичные файлы.grep -rs string directory– опция -s позволяет скрыть ошибки доступа к файлам, если у вас недостаточно прав на их чтение.grep -r --include=“string_file” string directory– опция--includeпозволяет вести поиск только по тем файлам, которые удовлетворяют маске поиска string_file. Опция –exclude применяется аналогично, но для исключения из поиска определенных файлов.grep -w string file– опция -w позволяет искать не вхождения строки в слова, а полностью совпадающие слова, например, без опции -w строка поиска abc будет соответствовать словам aabc, abc123 и т.д., а с опцией -w только словам abc.grep -c string file– опция -c позволяет вывести количество строк с найденными вхождениями строки string.grep -v string file– опция -v позволяет вывести строки, которые не содержат вхождения string.grep -lr string directory– опция l (строчная L) позволяет вывести только имена файлов, в которых есть хотя бы одно вхождение строки string.grep --color=always– опция--colorпозволяет задать подсветку найденных вхождений в строках.
Регулярные выражения на примере утилиты grep
Регулярные выражения — это специальным образом записанные строки, используемые для поиска символьных шаблонов в тексте. Чем-то они похожи на групповые символы в оболочке, но их возможности куда шире. Многие утилиты для работы с текстом в Linux и языки программирования включают в себя механизм регулярных выражений. Существует много диалектов регулярных выражений, однако большинство утилит в Linux соответствуют стандарту регулярных выражений POSIX. Их мы и рассмотрим.
Существуют два вида реализации регулярных выражений в стандарте POSIX – базовый Basic Regular Expression (BRE) и расширенный Extended Regular Expression (ERE). BRE поддерживают практически все POSIX-совместимые программы, а ERE позволяет создавать более сложные регулярные выражения, но поддерживается не всеми утилитами, однако grep поддерживает оба этих вида.
Простые регулярные выражения
В простых регулярных выражениях применяются следующие метасимволы: ^ $ . [ ] * \ -. Метасимволы – это категория символов для составления критериев поиска в регулярных выражениях. Простые символы принято называть литералами, например, выражение «dir» обозначает строку, соответствующую следующим критериям: в строке не меньше трех символов; в строке присутствуют символы «d», «i», «r», причем именно в таком порядке; между ними нет других символов. Символы, соответствующие сами себе (как «d», «i», «r»), и есть литералы. Для использования метасимвола в качестве литерала его необходимо экранировать обратной косой чертой (\). Некоторые метасимволы в регулярных выражениях имеют специальное значение в оболочке, поэтому при использовании их в регулярных выражениях строку с ними необходимо заключать в кавычки.
Метасимвол «.» соответствует любому символу в этой позиции (но не null или «пустота»). Пример использования: ls /bin | grep '.dir'.
Метасимвол звездочка «*» после другого символа в шаблоне означает, что этот символ может повторяться любое количество раз, в том числе и ни одного раза. Пример использования: ls /bin | grep 'mk*dir'.
Метасимволы «^» и «$» выполняют роль якорей. Якоря позволяют искать вхождение шаблона не просто в строке, а явно указать, что вхождение должно быть в начале строки (символ «карет» (^)) или в конце строки (символ «доллар» ($)). Регулярное выражение «^$» соответствует пустым строкам. Примеры использования: ls /bin | grep '^dir'; ls /bin | grep 'dir$'.
Метасимволы квадратные скобки «[]» позволяют указать множество, любой член которого будет удовлетворять символу в этой позиции. Например, ls /bin | grep '[km]dir'.
Все метасимволы, кроме двух, в квадратных скобках теряют свои специальные значения.
Метасимвол «^» сразу после «[» добавляет логическое «не», т.е. символу на этой позиции будет соответствовать любой символ, не входящий в множество, указанное в квадратных скобках. Например,
ls /bin | grep '[^km]dir'. Если символ «^» стоит в скобках не в начале, то он интерпретируется как обычный символ.Метасимвол дефис «-» определяет диапазоны символов. Можно задать диапазоны букв или цифр. Например,
ls /bin | grep '[o-z]dir';ls /dev | grep 'tty1[4-7]'.
В POSIX есть несколько классов, описывающих разные множества символов.
[:alnum:] — Алфавитно-цифровые символы; эквивалент диапазона [A-Za-z0-9] в ASCII.
[:alpha:] — Алфавитные символы; эквивалент диапазона [A-Za-z] в ASCII.
[:digit:] — Цифры от 0 до 9.
[:lower:] и [:upper:] — Символы нижнего и верхнего регистра соответственно.
[:space:] — Пробельные символы, включая пробел, табуляцию, возврат каретки, перевод строки, вертикальную табуляцию и перевод формата.
Расширенные регулярные выражения
В расширенных регулярных выражениях применяются следующие метасимволы:
Круглые скобки: ( );
Фигурные скобки: { };
Вопросительный знак: ?;
Символ плюса: +;
Вертикальная черта: |.
Для использования расширенных регулярных выражений утилитой grep необходимо использовать ключ -E.
Метасимвол вертикальная черта «|» означает логическое ИЛИ. Он позволяет задать два набора символов в шаблоне, вхождения каждого из которых будут найдены. Например:
Команда
echo "123" | grep -E '123|345'выведет на экран строку 123, так как подстрока 123 указана в параметре-E;Команда
echo "345" | grep -E '123|345'выведет на экран строку 345, так как подстрока 345 указана в параметре-E;Команда
echo "234" | grep -E '123|345'ничего не выведет на экран, так как подстрок 123 и 345 нет в строке.
Метасимволы круглые скобки «()» применяются для группировки условий.
Например, ls /dev | grep -E 'tty1(1|2|3)' выведет все строки, содержащие tty11, tty12 или tty13, а то же выражение без скобок ls /dev | grep -E 'tty11|2|3' выведет строки, содержащие или tty11, или 2, или 3.
Метасимвол вопросительный знак «?» после другого символа в шаблоне, означает совпадение с этим символом ноль или один раз. Другими словами, или этот символ есть в тексте, или его может не быть, например:
Команда
echo "13" | grep -E '12?3'выведет на экран строку 13, так как в параметре -E символ 2 не является обязательным;Команда
echo "123" | grep -E '12?3'выведет на экран строку 123, так как в параметре -E символ 2 допустим;Команда
echo "1223" | grep -E '12?3'ничего не выведет, так как символ 2 допустим только один раз.
Метасимвол знак плюс «+» после другого символа в шаблоне означает совпадение с этим символом один или более раз. Похож на символ «*», однако символ «*» допускает ни одного совпадения, а символ «+» минимум одно. Пример использования: ls /bin | grep -E 'mk+dir'.
Метасимволы фигурные скобки «{}» позволяют задать количество совпадений символа, после которого они идут:
{n} — Совпадение, если предыдущий элемент встречается точно n раз.
{n,m} — Совпадение, если предыдущий элемент встречается не менее n и не более m раз.
{n,} — Совпадение, если предыдущий элемент встречается n или более раз.
{,m} — Совпадение, если предыдущий элемент встречается не более m раз.
Примеры использования:
$ echo "13" | grep -E '12{1,3}3'
$ echo "123" | grep -E '12{1,3}3'
123
$ echo "1223" | grep -E '12{1,3}3'
1223
$ echo "12223" | grep -E '12{1,3}3'
12223
$ echo "122223" | grep -E '12{1,3}3'
Утилита sed
Sed – это потоковый редактор текста (от англ. stream editor), c помощью которого можно выполнять множество операций с файлами, например, поиск и замену, вставку или удаление. При этом чаще всего он используется именно для поиска и замены.
Sed позволяет редактировать файлы не открывая, что существенно ускоряет работу, чем при использовании того же vi. Помимо этого, sed поддерживает регулярные выражения, с помощью которых можно выполнять сложное сопоставление шаблонов.
Формат утилиты: sed [<параметры>] '<правила_отбора> <инструкции>' [файлы]
Параметры:
-E– использовать расширенный вариант регулярных выражений. При этом регулярное выражение в правилах отбора обрамляется символами слэша /регулярное выражение/.-e– используется, если в команде необходимо указать несколько инструкций. Он размещается перед каждой инструкцией.-i(--in-place) - производить изменения в указанном файле.-n– запрет вывода всех строк (по умолчанию выводятся все строки).
Правила отбора:
В соответствии с номером строк –
1,5– с первой по 5 строки,5,$- с пятой по последнюю строки.В соответствии с регулярным выражением.
Инструкции:
n– запрет вывода всех строк (по умолчанию выводятся все строки)p– вывод строк, попадающих под критерии отбора. Часто применяется с -nd– удаление строкi'текст'– вставка текста перед строкой, попадающей под критерии отбораa'текст'– вставка текста после строки, попадающей под критерии отбораc'текст'– замена строки, попадающей под критерии отбора на текстs/строка_поиска/строка_замены/– поиск и замена текста
Полную информацию по утилите sed можно найти в справке man sed.
Примеры использования:
Вывод первых 5 строк из файла /etc/passwd:
localadmin@astra:~$ cat /etc/passwd | sed -n '1,5 p'
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
Вывод 1 и 2 строк (удаление всех других) из файла /etc/passwd.
localadmin@astra:~$ cat /etc/passwd | sed '3,$ d'
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
Вывод строк с 990 по 999:
localadmin@astra:~$ cat /etc/passwd | sed -n -E '/99[0-9]/ p'
systemd-coredump:x:999:999:systemd Core Dumper:/:/usr/sbin/nologin
vboxadd:x:998:1::/var/run/vboxadd:/bin/false
Вставка текста перед найденной строкой:
localadmin@astra:~$ cat /etc/passwd | sed -e "/root/i Следующая строка содержит данные пользователя root:" | head -n5
Следующая строка содержит данные пользователя root:
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
Вставка текста после найденной строки:
localadmin@astra:~$ cat /etc/passwd | sed -e "/root/aПредыдущая строка содержит данные пользователя root" | head -n5
root:x:0:0:root:/root:/bin/bash
Предыдущая строка содержит данные пользователя root
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
Вставка текста до и после найденной строки:
localadmin@astra:~$ cat /etc/passwd | sed -e "/root/i----------------------" -e "/root/a | ----------------------" | head -n5
----------------------
root:x:0:0:root:/root:/bin/bash
----------------------
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
Замена найденного текста в строке:
localadmin@astra:~$ cat /etc/passwd | sed -n '/localadmin/ p'
localadmin:x:1000:1000:localadmin,,,:/home/localadmin:/bin/bash
localadmin@astra:~$ cat /etc/passwd | sed -e 's#/bash#/sh#' | grep localadmin
localadmin:x:1000:1000:localadmin,,,:/home/localadmin:/bin/sh
Утилита awk
AWK – это скриптовый язык, который полезен при работе в командной строке и широко применяется для обработки текста. Обработка текста идет построчно.
При использовании awk вы можете выбирать данные – один или более отдельных фрагментов текста – на основе заданного критерия отбора. Например, с помощью awk можно выполнять поиск конкретного символа, слова или шаблона во фрагменте текста, а также выбирать определённую строку или столбец. Возможности awk позволяют проводить сложную обработку текстов, составлять отчеты, проводить анализ информации и составлять тексты команд для последующего их выполнения интерпретатором.
Формат утилиты: awk [<параметры>] '<правила_отбора> {<действия>}' [<файлы>]
Параметры:
С помощью awk можно работать со строками как с полями строк в таблице. Для этого с помощью параметра -F можно задать разделитель, например, -F ': ', и обращаться к разделенным столбцам через встроенные переменные: $0 – вся строка, $1 – первое поле, $2 – второе поле и так далее. В переменной NF хранится значение количества полей в строке, а NR – хранит номер строки.
Действия:
В качестве действия могут использоваться команды вывода текста, такие как printf или print.
Можно использовать следующие правила отбора:
Регулярные выражения – обрамляются слэшами.
Операции сравнения – используется следующая конструкция: {переменная_номера_поля}{операнд}{значение}, например, $1<10. В качестве операндов используются:
Арифметические (сравнения): - >, >=, <, <=, ==, !=
Строковые (соответствия): ==, !=
Регулярные выражения (соответствия): ~, !~
Примеры использования:
Вывод имен пользователей с uid от 990 до 999:
localadmin@astra:~$ cat /etc/passwd | awk -F ':' '/99[0-9]/{print$1}'
systemd-coredump
vboxadd
Вывод имен, uid и оболочки пользователей с uid от 10 до 20:
localadmin@astra:~$ cat /etc/passwd | awk -F ':' '$3>10 && $3 < 20 {print $1,$3,$NF}'
proxy 13 /usr/sbin/nologin
Вывод id и команды запуска всех процессов, принадлежащих пользователю:
localadmin@astra:~$ ps aux | awk '$1~/localad/{print $2,$11}'
1084 /lib/systemd/systemd
1085 (sd-pam)
1107 fly-wm
1172 /usr/bin/dbus-launch
1173 /usr/bin/dbus-daemon
1196 /usr/bin/kglobalaccel5
1202 /usr/bin/VBoxClient
...
Полную информацию по утилите awk можно найти в справке man awk.
Текстовые редакторы
Текстовый редактор vim
Vim — это текстовый редактор, который Windows-пользователям покажется крайне необычным. Больше всего начинающих администраторов сбивает с толку то, что в этом редакторе используются несколько режимов ввода, основными из которых являются «командный» и «текстовый».
Приведем краткую инструкцию по применению:
Выполните команду
vi test.txt, чтобы открыть файлtest.txtдля редактирования.Сразу после запуска приложения вы находитесь в режиме ввода команд и можете, например, ввести команду выхода``:q`` затем нажмите Enter, чтобы закрыть программу.
Для редактирования документа вам потребуется переключиться в текстовый режим с помощью клавиши Insert. Нажимая клавишу Insert несколько раз, вы можете выбрать подрежим вставки или замены.
Для того чтобы скопировать текст, просто выделите его с помощью указателя мыши. Для того чтобы вставить текст из этого буфера, наведите указатель мыши в желаемое место и нажмите на колесико мыши. Вы можете так же использовать более привычный буфер обмена, для вставки которого используются горячие клавиши Ctrl + V — для этого при выделении текста удерживайте клавишу Shift, а для копирования вставки команды из контекстного меню, которое доступно по нажатию правой кнопки мыши.
Чтобы вернуться обратно в режим команд и сохранить изменения, вам нужно нажать клавишу Esc и ввести команду
:wq.Для выхода без сохранения используйте команду
:q!.
За счёт командных функций Vim существенно повышает скорость работы с текстами, поэтому его выбирают профессионалы, которым требуется высокая производительность в работе из консоли. Однако, довести необходимые умения до автоматизма будет непросто.
Учебник vimtutor
После установки редактора Vim у вас появляется доступ к встроенному учебнику по работе с приложением, который можно открыть с помощью команды vimtutor. При этом открывается копия файла, поэтому вы можете практиковаться, не опасаясь повредить содержание учебника. Освоение Vim крайне желательно начать с изучения материалов этого пособия.
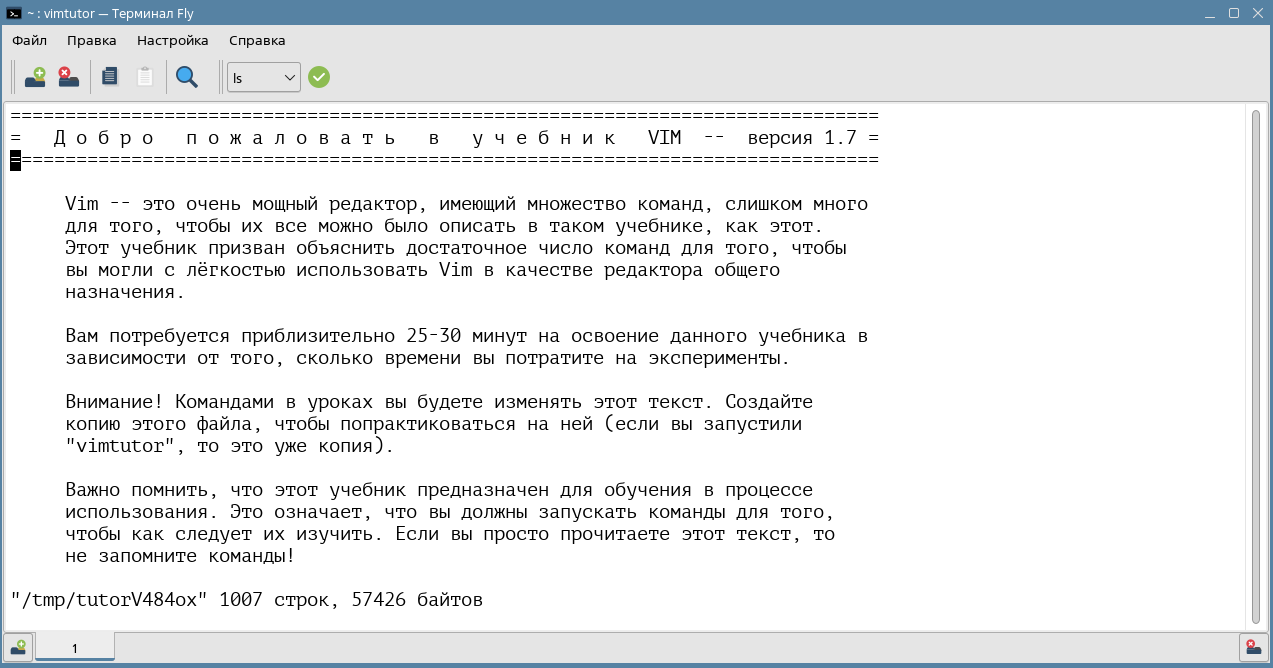
Далее будут рассмотрены основные приемы работы с Vim.
Запуск, сохранение и завершение работы с Vim
Запустить Vim не сложно, сложно из него выйти. Для запуска достаточно вызвать команду vim [опции] [имя_файла].
Ниже перечислены некоторые опции запуска:
-R– открыть в режиме «только чтение»;
-g– включить графический режим;
-w- сохранить все действия в файл;
-b– воспользоваться двоичным режимом, чтобы редактировать исполняемые файлы;
-d– найти различия в файлах (потребуется указать несколько файлов для открытия);
-n– отключить функцию автоматического сохранения для восстановления файла при ошибке;
«+команда»**— эта опция отвечает за выполнение команды после запуска редактора;
+номер— перемещение курсора к определённой пользователем строке после запуска;
+/шаблон— найти нужный участок в шаблоне и переместить курсор к его началу.
Запустим vim vim_test.txt. Сейчас мы находимся в командном режиме. Чтобы выйти из Vim, необходимо ввести одну из команд:
:q– выйти из редактора, если не было произведено изменений. В противном случае он не даст выйти этим способом.:q!– выход без сохранения. Более быстрый и удобный способ ввести ZQ.:qw– сохранить и выйти. Более быстрый и удобный способ ввести ZZ.
Команда :w просто сохранит текущие изменения, и вы сможете продолжить редактирование файла.
Работа в командном режиме
Введенные в этом режиме символы воспринимаются как команды. Можно повторять команды несколько раз, вводя команду и цифру, или уточнять область действия команд. Например, ввод dl удалит символ под курсором, dw удалит слово целиком, а d3w удалит 3 слова справа от курсора.
Но следует понимать, что у вас при этом должна быть включена английская раскладка.
Команды навигации по тексту:
h, l , j или k – перемещают курсор влево/вправо и вверх/вниз, однако проще будет использовать стрелочки мыши;
w или b – переместить курсор на 1 слово влево или вправо;
H – уйти в верхнюю часть экрана;
L – уйти в нижнюю часть экрана;
G – пролистать до конца файла;
zz, zt, zb – перемещать по экрану строку с курсором в середину/вверх/вниз;
Ctrl + u или Ctrl+d – прокрутить область просмотра в верхнем или нижнем направлении на полстраницы.
Команды для вставки и копирования:
p или P – вставить текст после курсора или перед ним;
y – скопировать символ;
yy или Y – скопировать целую строку.
Команды для отмены и удаления:
u – отменить последнее действие;
U – отменить последнее действие в указанной строке, где стоит курсор;
d – удалить символ;
dd – удалить строку целиком;
D – удалить всё, что находится на участке от курсора до конца строки;
dt – удалить часть текста, которая находится между местом курсора и следующим вхождением конкретного символа;
ciw – удалить конкретное слово и сразу переключиться в режим ввода;
C – удалить текст, начиная от места курсора и до конца строки, затем снова автоматически происходит переход в режим ввода.
Ещё несколько полезных команд:
v – выделить текст;
ggvG= – выровнять текст во всём файле (переместиться в начало, переключиться на режим VISUAL, выделить весь текст документа, настроить отступ выделенных строк);
. – повторить ещё раз последнюю команду;
n или N – продолжить поиск вперёд или назад;
~ – переключить регистр у символа, который выделен или на котором находится курсор;
/шаблон – искать вхождение;
%s/шаблон/заменить – заменить первое слово вторым.
Работа в текстовом режиме
Для переключения в текстовый режим, в котором введенные символы будут восприниматься как набираемый текст, нужно нажать клавишу Insert. Повторное нажатие Insert позволяет переключаться между текстовыми подрежимами вставки и замены.
Для возврата в командный режим достаточно нажать клавишу Esc.
Команды для перехода в текстовый режим:
I (строчная буква i) – переключиться в текстовый режим и перейти в начало строки;
A – переключиться в текстовый режим и перейти в конец строки;
a – переключиться в текстовый режим и перейти к следующему символу;
r – заменить один символ;
R – заменить несколько символов подряд;
o – создать строку снизу;
O – создать строку выше.
Режим командной строки
В режиме командной строки ввод команды начинается с ввода символа «:». Мы уже познакомились с ним, когда рассматривали завершение работы и сохранение файла. Ниже представлены некоторые другие команды этого режима:
:e файл– создать новый файл;:r файл– вставить содержимое этого файла в текущий файл;:r!– задать выполнение команды оболочки и вставку полученного ответа в Vim;:buffers– просмотреть открытые файлы;:set переменная=значение– задать значение переменной для управления процессами редактора.
Визуальный режим
В этом режиме с помощью команд навигации можно выделить часть текста (или весь текст) для его дальнейшего редактирования. Это удобно, так как пользователь видит выделенный участок.
Использование визуального режима сводится к выполнению трёх операций:
Находясь в командном режиме, нажмите горячую клавишу v, чтобы начать выделение текста.
Переместите курсор в конец визуального фрагмента для выделения текста.
Введите команду-оператор, которая выполнит действия над выделенным текстом. Например, если вы напечатаете символ ~, то будет изменен регистр символов и весь текст станет прописными буквами.
Приведем полезные команды-операторы:
y — скопировать текст в буфер обмена
p — вставить текст из буфера обмена
~ — изменить регистр символов
d — удалить выделенный текст
Кроме посимвольного режима v есть еще построчный V и режим блоков Ctrl + V. С дополнительной и информацией о Vim вы можете ознакомится в справке man vim и по ссылке https://ru.wikibooks.org/wiki/Vim
Текстовый редактор nano
Текстовый редактор nano входит в набор программ GNU и является стандартным консольным редактором для многих дистрибутивов Linux. Главное преимущество nano заключается в простоте использования — работать с ним так же просто, как в notepad.exe, поэтому у вас получится довольно быстро освоить его на высоком уровне для решения любых задач.
Для запуска достаточно вызвать команду nano [опции] [имя_файла].
Некоторые из опций:
+номер- указать строку в файле, с которой нужно начинать редактирование;-B- создавать резервную копию для файла при сохранении;-С- папка для резервной копии;-D- выводить текст жирным;-E- конвертировать табуляции в пробелы;-I- не читать конфигурацию из файлов nanorc;-P- запоминать и восстанавливать позицию курсора во время последнего редактирования;-m- включить поддержку мыши;-v- режим только для чтения, вы не можете сохранить файл.
Запустим текстовый редактор nano test_nano.txt.
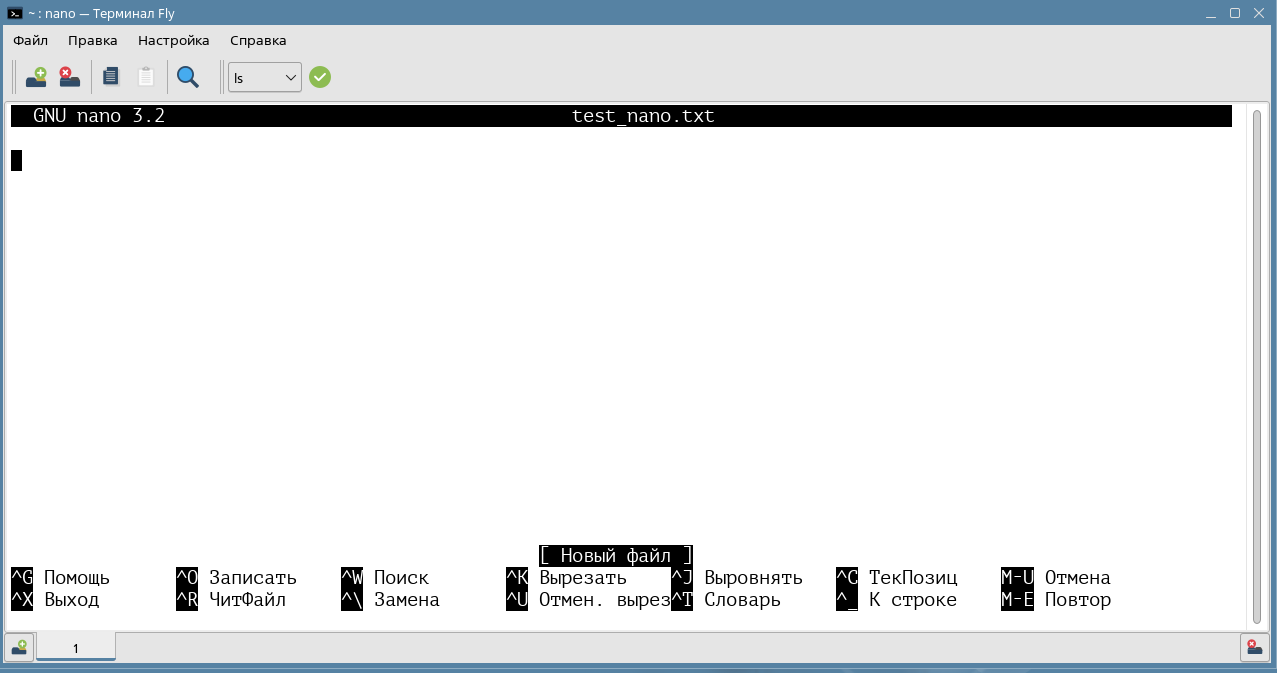
В отличие от Vim, тут нет особого режима, можно перемещаться по тексту и сразу редактировать его. В нижней части окна показана подсказка по командам, которая может меняться в зависимости от текущего состояния. В комбинациях используются связки клавиш Ctrl или Alt с другими клавишами. Напоминаем, что символ ^ является кратким обозначением клавиши Ctrl.
Полный список команд доступен по нажатию клавиши F1 или сочетания Ctrl +G.
Редактор nano может поддерживать поиск по регулярным выражениям. Для этого в конфигурационном файле в профиле пользователя ~/.nanorc должен быть установлен параметр set regexp.
В редакторе можно включить подсветку синтаксиса для популярных языков программирования. Для этого в конфигурационный файл ~/.nanorc с помощью директивы include нужно включить файлы с настройками подсветки, находящиеся в /usr/share/nano. Например, для подсветки sh нужно добавить строку «include /usr/share/nano/sh.nanorc».
Текстовый редактор mcedit
Редактор mcedit устанавливается вместе с файловым менеджером Midnight Commander и имеет схожий интерфейс.
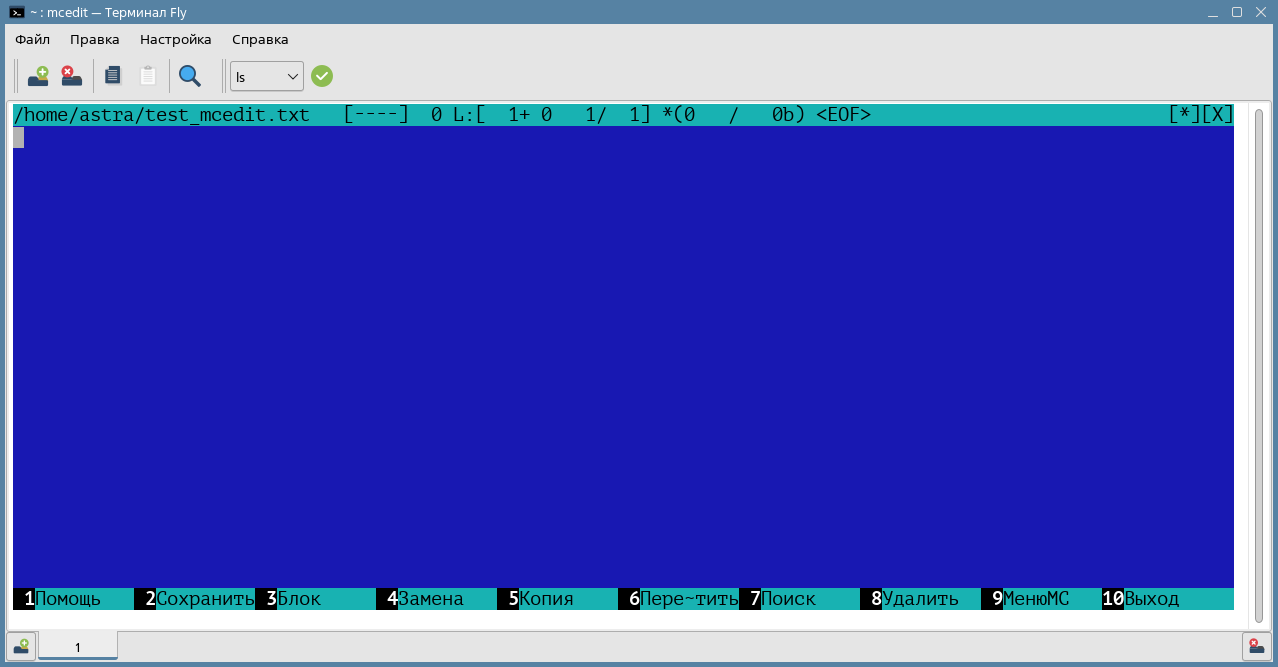
В нижней строке перечислены базовые команды, которые выполняются с помощью функциональных клавиш F1-10. Например, справка вызывается по нажатию F1, а основное меню клавишей F9.
Как и nano, редактор mcedit поддерживает работу с регулярными выражениями и подсветку синтаксиса популярных языков программирования и конфигурационных файлов. Для ручного управления подсветкой можно воспользоваться настройкой .
Графический текстовый редактор kate
Графический текстовый редактор kate имеет интуитивно понятный интерфейс и предоставляет большие возможности по настройке. По функциональности он очень похож на notepad++, т.е. сильно больше блокнота, но меньше Visual Studio Code.
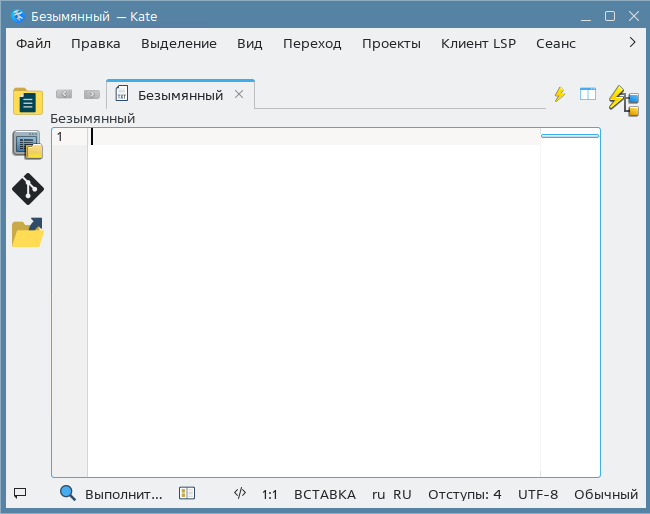
Как и упомянутые выше редакторы, kate поддерживает работу с регулярными выражениями и подсветку синтаксиса языков программирования и конфигурационных файлов. Рекомендован к использованию новичкам (и не только) в графическом режиме.
Практика и тестирование
Заключение
В этом модуле мы рассмотрели инструменты, с помощью которых можно просматривать и редактировать текстовые документы, выполнять по ним поиск, сортировку и фильтрацию, в том числе с использованием регулярных выражений. Мы рассмотрели возможности нескольких текстовых редакторов, доступных в Astra Linux «из коробки», и закрепили полученные знания на практике. То, какими инструментами пользоваться в повседневной работе, каждый выбирает сам, но проблем с их недостатком у нас теперь точно не будет.
Темой следующего модуля будет управление локальными пользователями и группами в Astra Linux, информация о которых, кстати, хранится в обычных текстовых файлах.
Дополнительные источники информации
Регулярные выражения можно создавать и тестировать на сайте regex101
Библиотека регулярных выражений RegExLib
С дополнительной и информацией о Vim вы можете ознакомится в справке
man vimи по ссылке https://ru.wikibooks.org/wiki/Vim
Обратная связь
Если остались вопросы, то их всегда можно задать в специальной теме.