Модуль 20. Сеть и стек TCP/IP, управление сетевыми интерфейсами
Введение
В этом модуле мы разберем, как работает сетевой стек TCP/IP вообще и в Linux в частности, что крайне важно для уверенного сопровождения инфраструктуры домена, где большинство компонентов взаимодействуют между собой по компьютерной сети даже в тех случаях, когда находятся на одном хосте.
Тема эта крайне специфичная, так как на обывательском уровне все знают, что такое эти Интернеты, а в базовых вопросах маршрутизации ориентируются уже только два админа из десяти. И дело тут даже не в наличии или отсутствии сертификатов CCNA/MTNA, так как в стране достаточно ребят, у кого с бумажками все хорошо, а со знаниями не очень.
Времени у нас совсем немного, поэтому по принципу «20 на 80» будем рассматривать в основном IPv4, останавливаясь только на самых основных моментах, которые считаем принципиально важными для понимания этой технологии. Легкой прогулки не обещаем, но высокая в небе звезда уже зовет в путь.
Основы компьютерных сетей
История вопроса
Когда компьютеры только зародились, их было очень мало и о сетях никто не думал. Но по мере того, как вычислительная техника становилась доступнее, идеи организации обмена данными между ЭВМ начали набирать популярность. Сначала это были соединения типа «точка-точка», затем задумались о более сложных топологиях.
Значительную роль в развитии этих технологий сыграл военный проект ARPA от наших западных партнеров, целью которого было, конечно же, не создание сети военной связи, устойчивой к ядерному нападению, а совместное использование ресурсов в сфере сотрудничества между университетами, частными технологическими компаниями… и ребятами в погонах.
Объединяем два компьютера «точка-точка»
Для того чтобы связать два компьютера между собой, даже никакого сетевого оборудования не требуется, достаточно один конец патчкорда воткнуть в сетевую карту первого компьютера, а второй конец — в сетевую карту второго компьютера.
Раньше для соединения однотипных устройств нужен был хотя бы специальный кабель с перекрестной обжимкой, а теперь у всех сетевых карт порты Auto-MDI(X), поэтому они автоматически распознают тип кабеля и можно использовать обычные патчкорды с прямой обжимкой, которая предусматривает одинаковый порядок жил на обоих концах.
Примечание
Сисадмины иногда задаются вопросом: «А нужно ли запоминать правильный порядок цветов витой пары или достаточно обжать кабель одинаково с двух сторон?». И мы вам ответим, что правильный порядок, во-первых, уменьшает помехи, а во-вторых, исключает путаницу, когда на вашей стороне только один конец провода, а второй за стенкой у провайдера.
Для запоминания порядка цветов по стандарту 568B есть простое и универсальное мнемоническое правило: «Сто патчкордов обжимаем, и цвета запоминаем…». Работает не только с патчкордами )))
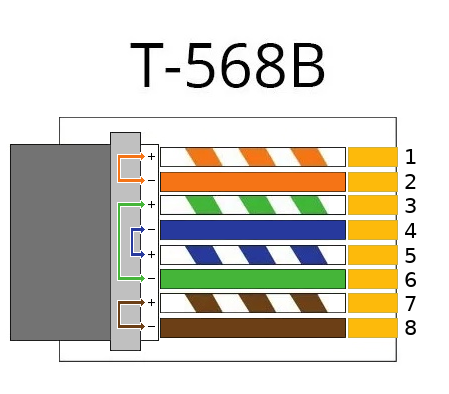
бело-оранжевый
оранжевый
бело-зеленый
синий
бело-синий
зеленый
бело-коричневый
коричневый
Теперь осталось только правильно выставить три основных сетевых настройки:
IP-адрес – это уникальный числовой идентификатор компьютера в сети, по которому один компьютер может обратиться к другому.
По стандарту IPv4 адрес является последовательностью из 32 бит, которую обычно представляют в виде четырех целых чисел в диапазоне 0 — 255, разделенных точками, например,
192.168.1.1. Учитывая, что эти числа кодируются восемью битами, их также называют иногда октетами.Маска – это последовательность из 32-бит, с помощью которой компьютер определяет, находится ли «собеседник» в одной сети вместе с ним. Если IP-адрес пункта назначения принадлежит к той же сети, то компьютер будет отправлять пакеты напрямую в сетевой интерфейс. А если адрес будет из другой сети, то пакеты пойдут через шлюз.
Особенность сетевой маски заключается в том, что это непрерывная последовательность единичек и нулей, например,
11111111 11111111 11111111 00000000. Поэтому кроме полной записи255.255.255.0, к которой нас приучили в Windows, есть еще короткая запись /24 (называемая префикс), где число соответствует количеству единичек в начале маски. В мире Linux маску часто указывают сразу вместе с IP-адресом, например,192.168.1.1/24.Учитывая, что единички маски указывают на то, какая часть IP-адреса будет определять его принадлежность к сети, короткую запись называют также префиксом сети. Для упрощения понимания приведем несколько примеров:
Маска сети |
Префикс сети |
Двоичная запись маски |
|---|---|---|
0.0.0.0 |
/0 |
|
128.0.0.0 |
/1 |
|
192.0.0.0 |
/2 |
|
255.0.0.0 |
/8 |
|
255.255.0.0 |
/16 |
|
255.255.255.0 |
/24 |
|
255.255.255.255 |
/32 |
|
Примечание
Метод с использованием маски называют бесклассовой адресацией (англ. Classless Inter-Domain Routing, англ. CIDR), а до него использовалась классовая адресация, которая умерла еще в 90е годы ввиду своей неэффективности, но авторы некоторых статей и учебников до сих пор тащат эту «свежатину» про классы A, B, C, D, E, забивая людям голову ненужной информацией.
Шлюз по умолчанию – это адрес узла в компьютерной сети, через который компьютер может связываться с устройствами из других сетей, например, выходить в Интернет.
Для связи компьютер-компьютер маска и шлюз не имеют значения, т.к. шлюз вообще не используется, а маска по умолчанию будет длиной 24 бит, что вполне подойдет. Настроим указанную схему в графическом симуляторе сети GNS3 и проверим с помощью команды ping доступность второго компьютера, см. рис. 118.
Примечание
Кстати, приложение GNS3 является хорошей альтернативой симулятору Cisco Packet Tracer. С помощью этого приложения вы сможете создавать работоспособные модели сети, в том числе с использованием VLAN’ов, настраивать взаимодействие между виртуальными машинами, включать в состав сети программные маршрутизаторы, например, на базе RouterOS от Mikrotik. Если вы решите отточить свои навыки работы с сетями, то обязательно скачайте виртуальную машину с GNS3, и этот инструмент вам очень поможет!
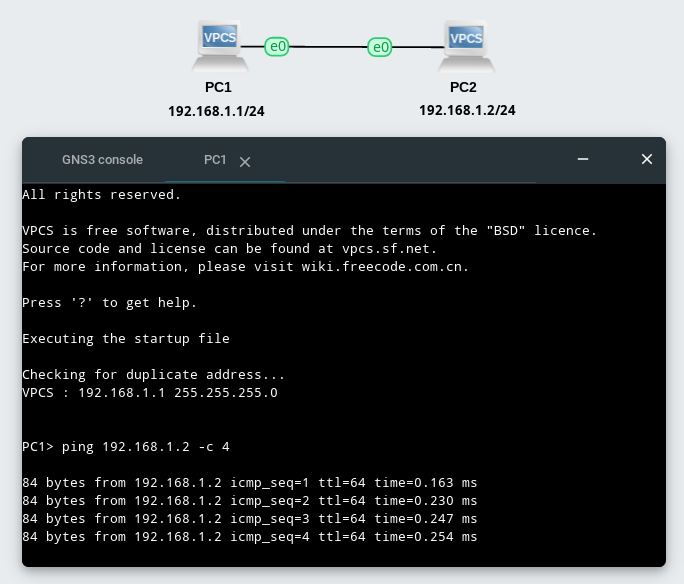
рис. 118 Проверка доступности второго компьютера в симуляторе GNS3
Примечание
Для исключения конфликтов в использовании одних и тех же IP-адресов их выдачу поручили некоммерческой организации ICANN. Но выдача адресов – это дело не быстрое, а еще «белых» публичных адресов не так много, чтобы назначать их на каждый компьютер, поэтому для внутренних нужд предприятий определили несколько подсетей частных адресов:
Сеть 192.168.0.0/16 – обычно используется Интернет-провайдерами для домашних устройств физических лиц.
Сеть 10.0.0.0/8 – рекомендуется для использования на предприятиях.
А для тех, кто хочет быть «не как все», есть еще диапазон 172.16.0.0 — 172.31.255.255.
Объединяем несколько компьютеров в топологии «звезда»
Связывать компьютеры «один к одному» могли и раньше, но с появлением сетей стало возможно объединять их в цепочки, кольца и делать полную связанность «все со всеми». Но на предприятиях наибольшее распространение получила все же топология «звезда», которая предполагает, что компьютеры объединяются в сеть через один центральный узел, см. рис. 119.
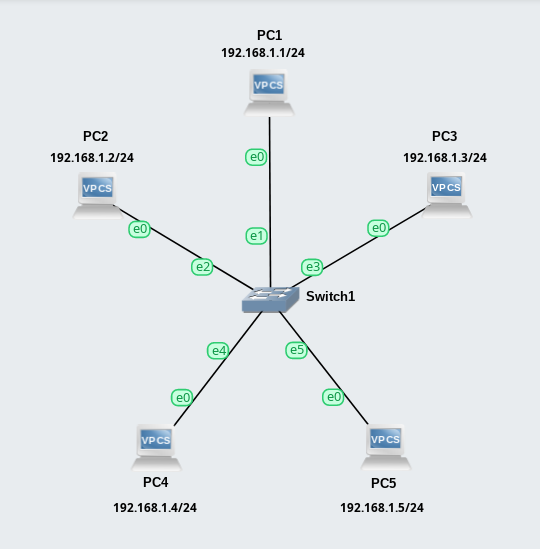
рис. 119 Объединение компьютеров в топологии «звезда»
Топология звезда является очень простой, ее можно легко масштабировать, а при выходе из строя обычного компьютера это никак не скажется на работе сети в целом.
В качестве центрального узла может выступать обычный компьютер, но в этом случае потребуется установить в него сразу несколько сетевых карт и сделать специфические настройки. Поэтому гораздо проще, дешевле и эффективнее воспользоваться специальными устройствами, которые называются сетевыми коммутаторами.
Первые коммутаторы назывались хабами и представляли собой примитивные устройства, которые умели только ретранслировать входящий сигнал на все остальные порты. В дальнейшем их вытеснили свитчи, которые научились запоминать, на каком порту какой MAC-адрес засветился, чтобы «не засорять эфир». И это не считая того, что свитчи стали оснащать так называемыми ASIC-микросхемами, которые способны решать задачу коммутации значительно эффективнее, чем центральный процессор обычного ПК.
Основы маршрутизации
Когда мы включаем на компьютере сетевой интерфейс, его IP-адрес, маска и шлюз используются для настройки таблицы маршрутизации. В системе Windows посмотреть ее можно с помощью команды route print, см. рис. 120.
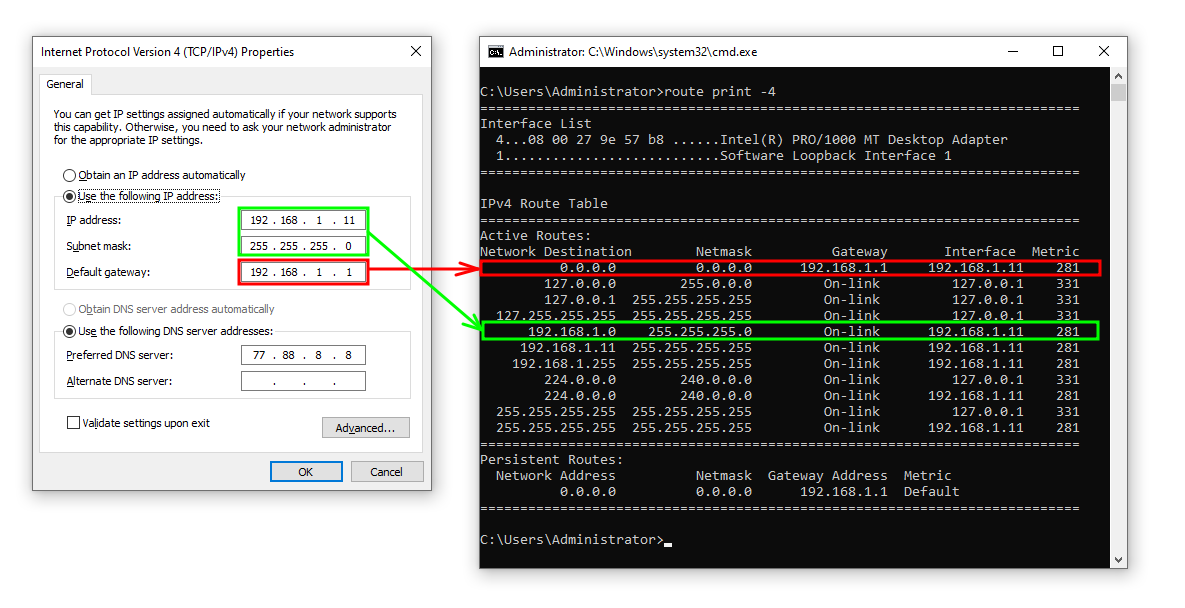
рис. 120 Соответствие настроек сетевого интерфейса с записями в таблице маршрутизации в Windows
В системе Astra Linux для настройки сети в стиле Windows можно воспользоваться графическим апплетом приложения NetworkManager, а список маршрутов посмотреть утилитой route, см. рис. 121.
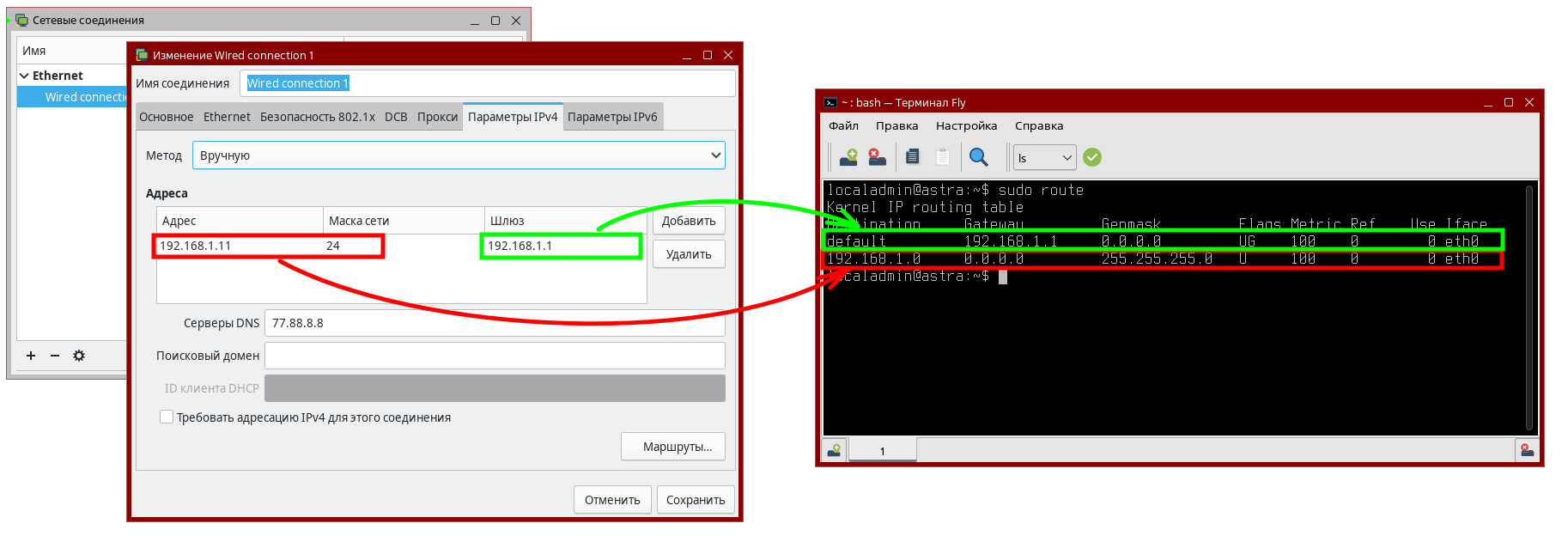
рис. 121 Соответствие настроек сетевого интерфейса с записями в таблице маршрутизации в Astra Linux
Вне зависимости от того, где вы настраивали сеть, обратите внимание на следующие маршруты:
IP-адрес и маска из настроек сетевого интерфейса определяют маршрут в локальную сеть 192.168.1.0/24, для которого в качестве шлюза указано значение On-link, т.е. пакеты нужно отправлять напрямую в сетевой интерфейс.
Шлюз по умолчанию из настроек сетевого интерфейса определяет маршрут в сеть 0.0.0.0/0, для которого в качестве шлюза указан IP-адрес 192.168.1.1.
Когда мы обращаемся к какому-нибудь хосту по IP-адресу, наш компьютер отбирает из таблицы маршрутизации те маршруты, в сети которых попадает запрашиваемый адрес, а затем из найденных маршрутов выбирает наиболее подходящий.
Выбор маршрута при обращении к хосту из локальной сети
Если мы обратимся к хосту с IP 192.168.1.12, то этот адрес попадает в сеть 192.168.1.0/24, т.к. при побитовом умножении этого числа на маску 255.255.255.0 мы получим тот же самый адрес сети 192.168.1.0. Как вы помните «1 & 1 = 1» и «1 & 0 = 0», поэтому первые 24 бита останутся без изменений, а последние 8 бит будут обнулены, см. рис. 122.

рис. 122 Получение адреса сети путем побитового умножения IP-адреса на маску
Но обратите внимание, что крупные сети, у которых значение префикса меньше, как матрешки могут вбирать в себя IP-адреса более мелких сетей. А в сеть 0.0.0.0/0 так вообще попадают все возможные адреса IPv4, см. рис. 123, поэтому данный маршрут тоже подходит.
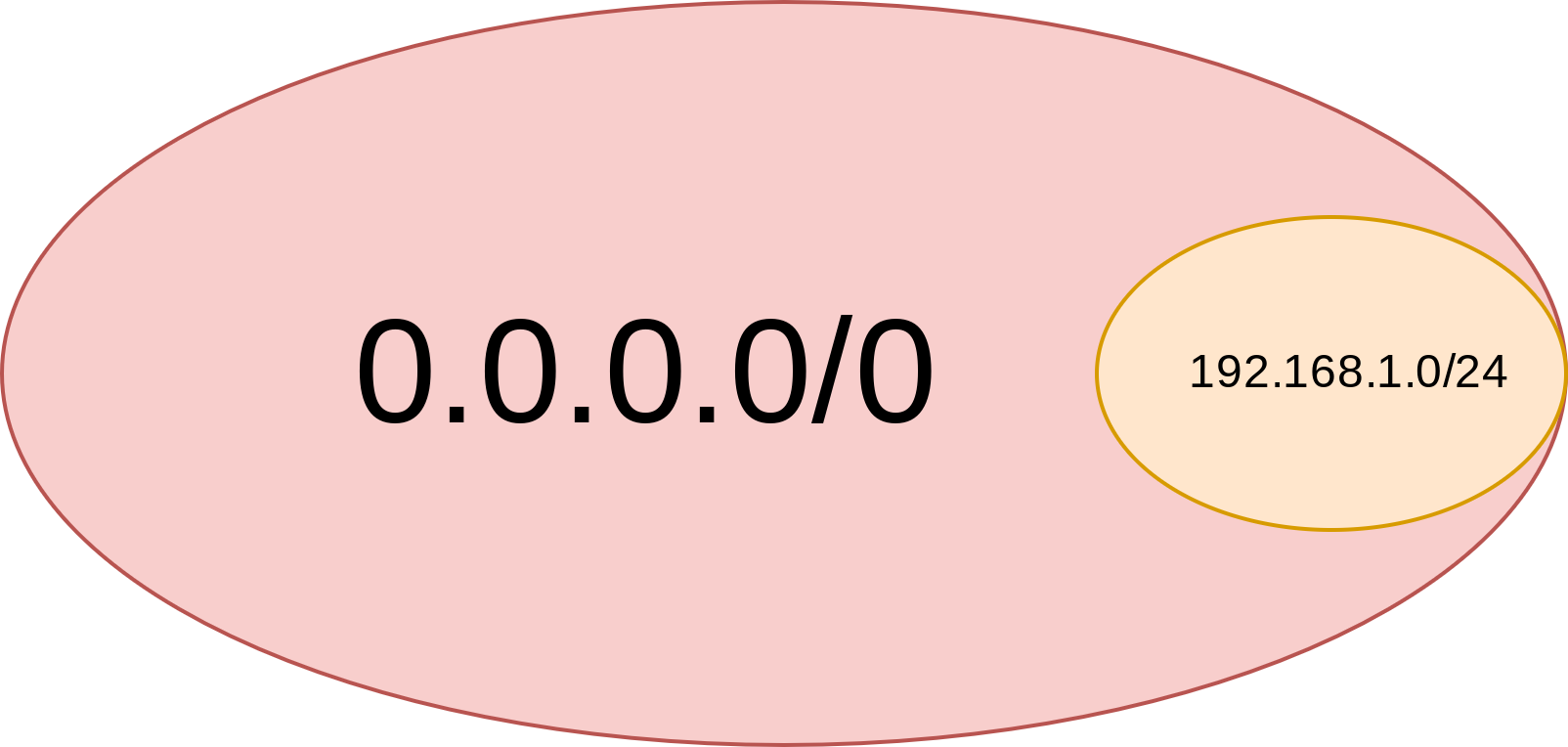
рис. 123 Вложенность сетей с разной длиной префикса
Если IP-адресу назначения соответствует несколько маршрутов, то выбирается тот из них, который является более специфичным, т.е. у которого больше значение префикса сети. Именно поэтому мы пойдем по маршруту локальной сети (192.168.1.0/24), а не через шлюз по умолчанию (0.0.0.0/0), т.к. 24 > 0.
Довольно часто администраторы ошибаются, полагая, что выбор маршрута осуществляется на основании метрики, которая учитывает количество промежуточных узлов, задержки и пропускную способность канала. Метрика тоже учитывается, но принимается во внимание только в тех случаях, когда в одну и ту же подсеть ведут несколько маршрутов с одинаковыми префиксами. Если же префиксы разные, то решение принимается исключительно по специфичности маршрута.
Выбор маршрута при обращении к хосту из сети Интернет
Стоит рассмотреть еще случай с обращением к хосту с IP 77.88.8.8, который находится в сети Интернет. С одной стороны, адресу назначения подходит только один маршрут с сетью 0.0.0.0/0, но в качестве шлюза у этого маршрута указан IP-адрес, а не физический интерфейс (On-link).
Чтобы определить физический интерфейс, куда нужно отправлять пакеты, чтобы они дошли до шлюза с IP-адресом 192.168.1.1, компьютеру нужно будет выполнить повторный проход по таблице маршрутизации, что называется рекурсивным поиском маршрута.
Стек протоколов TCP/IP
В предыдущем разделе мы рассматривали больше прикладные аспекты работы компьютерных сетей, а теперь начнем погружение в теорию, которая лежит в основе сетевых технологий.
Модель TCP/IP vs OSI
Стек протоколов TCP/IP был разработан в рамках проекта ARPA в конце 70-х годов, а 1 января 1983 сеть ARPANET окончательно перешла на новый стек, и эту дату принято считать официальным днем рождения Интернета.
Основная идея, заложенная в эту технологию, заключалась в разделении процесса сетевого взаимодействия на несколько стандартизированных уровней, каждый из которых должен был выполнять строго определенные функции, за счет чего можно было добиться совместимости приложений и оборудования, разрабатываемых независимыми производителями.
Идею многослойной архитектуры сетевого взаимодействия впервые сформулировали еще в конце 60-х годов, и ее развитием занималось параллельно сразу несколько команд. Например, широко известны усилия Международной организации по стандартизации (ISO) при поддержке Великобритании, которые привели к созданию модели OSI (англ. Open Systems Interconnection model — модель взаимодействия открытых систем). Однако победу в этом заплыве одержала все-таки команда в звездно-полосатых купальниках.
В наши дни OSI используют как эталонную модель для обучения, т.к. она является наиболее структурированной и проработанной, но мало кто знает, что у нее была вполне реальная практическая реализация. Например, в домене мы используем LDAP-протокол (Lightweight Directory Access Protocol — облегченный протокол доступа к каталогам), и его облегченность выражалась в том, что первый LDAP-сервер был просто шлюзом для доступа TCP/IP-клиентов к DAP-каталогам, которые работали на сетевом стеке OSI.
Несмотря на то, что модель OSI не используется сейчас на практике, коммутационное оборудование довольно часто относят к категориям L2 и L3, подразумевая канальный и сетевой уровни модели OSI соответственно. Например, L3-свитч – это сетевое устройство, функционирующие на третьем уровне OSI, которое предоставляет возможность коммутации и маршрутизации на базе IP-адресов. Поэтому будет полезно посмотреть, как уровни этих моделей соотносятся между собой, см. рис. 124.
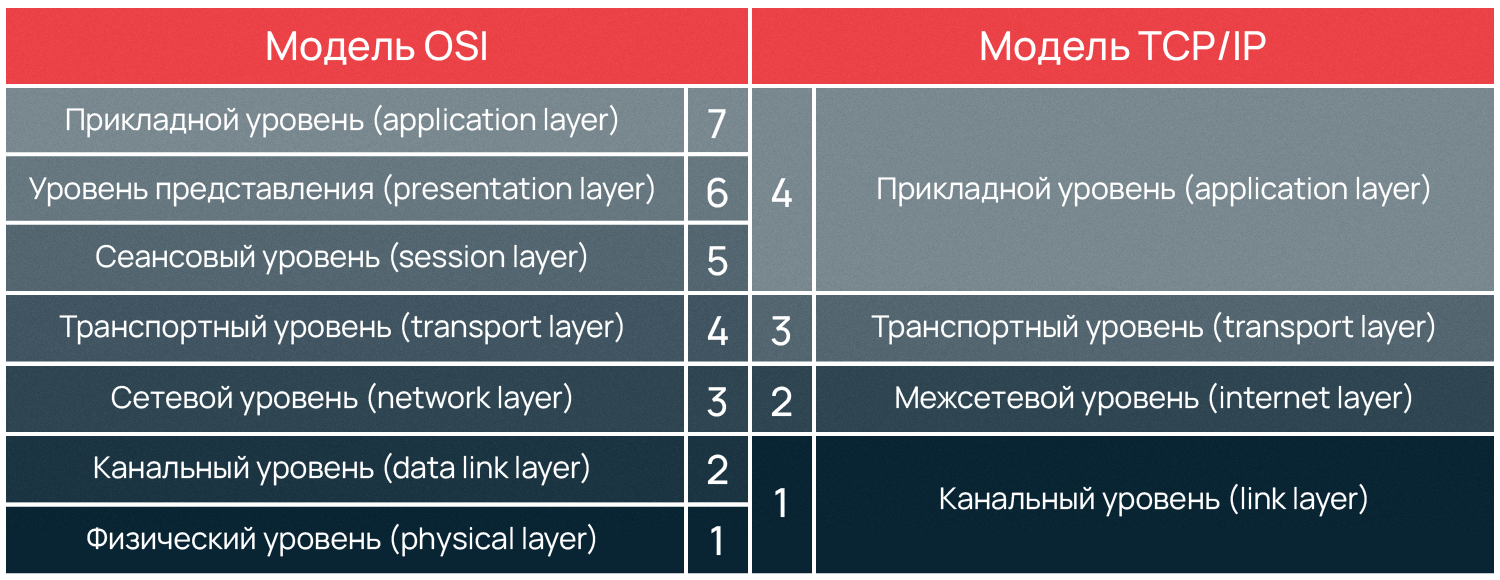
рис. 124 Сопоставление уровней OSI и TCP/IP
Уровни модели TCP/IP
Рассмотрим работу сетевой модели TCP/IP на примере HTTP-запроса к веб-серверу. Этот пример позволит пройти по всем уровням и рассмотреть каждый из них подробнее.
Прикладной уровень
На самом верхнем уровне сетевой модели TCP/IP находится прикладной уровень. Тут работают приложения, например, это может быть веб-сервер Apache, Nginx или что-то еще. Протоколы прикладного уровня определяют бизнес-логику взаимодействия пользователя с приложением.
Например, веб-сервер работает по протоколу прикладного уровня HTTP, в соответствии с которым в каждом запросе к серверу передается адрес запрашиваемой страницы, требуемый метод обработки запроса (GET, POST и т.д.), заголовки и при необходимости тело сообщения, в котором могут содержаться данные веб-формы. А в ответ веб-сервер возвращает нам, к примеру, контент страницы или код состояния 404, который указывает, что запрошенный нами контент не найден.
Примерно ту же роль выполняют прикладные протоколы SMTP, POP3 и другие — меняется только бизнес-логика приложений, а, следовательно, набор методов для взаимодействия с сервером, способы кодирования информации и т.п.
Транспортный уровень
Данные пользовательских приложений передаются по компьютерной сети внутри пакетов транспортного уровня. Основными протоколами тут являются:
TCP (Transmission Control Protocol — протокол управления передачей) — устанавливает двустороннее соединение и гарантирует доставку сообщений.
Этот протокол транспортного уровня используется подавляющим большинством протоколов прикладного уровня, например, HTTP, Kerberos, LDAP, SMB и другими, так как надежность обычно важнее скорости.
Кстати, огромную роль этого протокола для всей технологии в целом разработчики отметили внесением его имени в общее название стека.
UDP (User Datagram Protocol — протокол пользовательских датаграмм) — предполагает отправку сообщений в одну сторону без обратной связи.
Этот протокол транспортного уровня широко используется в приложениях, для которых скорость важнее надежности или не требуется установление сессии, например, NTP, DNS, DHCP, потоковое аудио и видео (SIP и IPTV или, вернее, RTP).
Пакеты TCP/UDP, или как их еще называют сегменты, включают данные пользовательских приложений и добавляют к ним свой заголовок с необходимой метаинформацией – этот процесс называют инкапсуляцией, см. рис. 125.
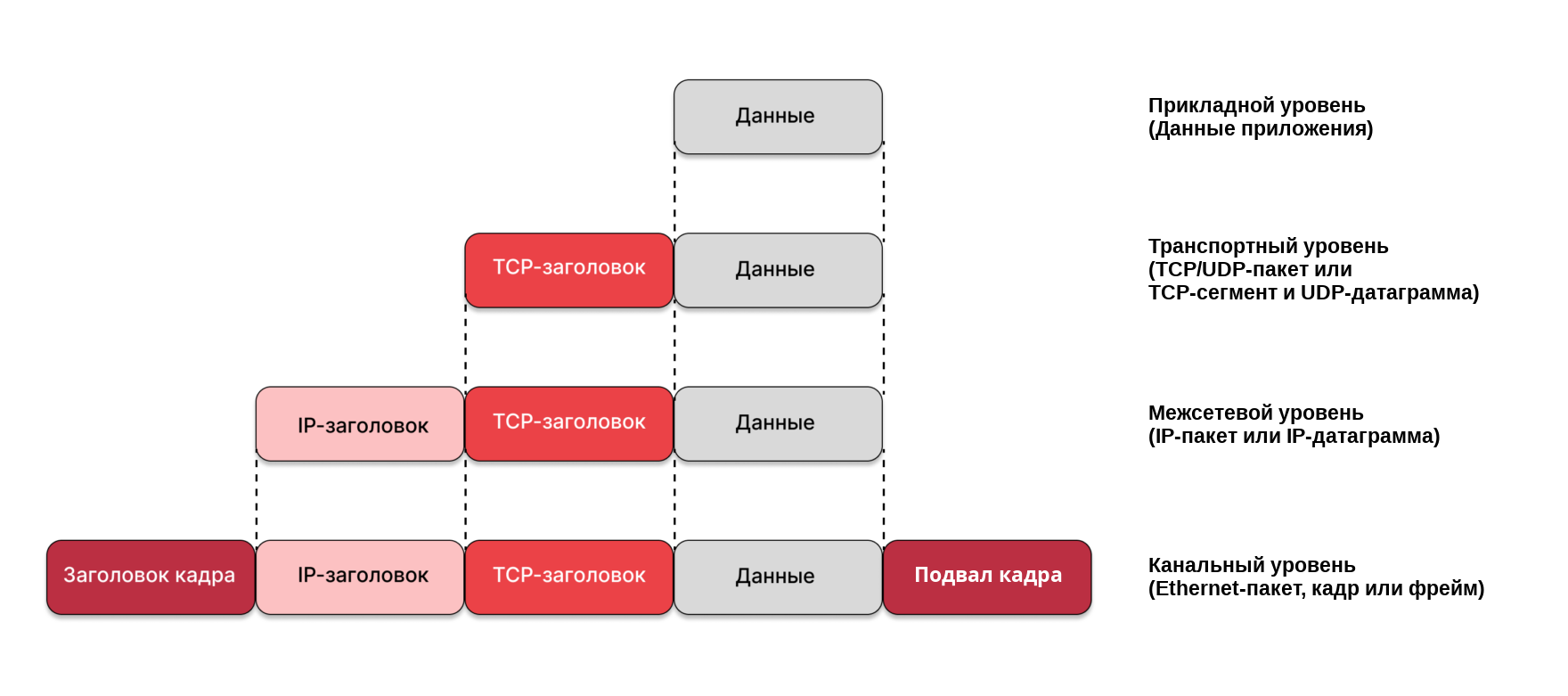
рис. 125 Инкапсуляция пользовательских данных по стеку TCP/IP
Среди параметров, которые передаются в заголовке TCP/UDP-сегмента, наиболее важными являются порты источника и приемника. Порт представляет собой целое число в диапазоне от 0 до 65 535, с помощью которого операционная система обеспечивает одновременную работу сразу множества сетевых приложений.
Когда мы запускаем на компьютере сетевое приложение, оно открывает какой-то конкретный порт, то есть просит операционную систему пересылать ему все входящие пакеты, внутри которых порт получателя будет иметь указанное значение. Поэтому, когда говорят, что сервер был взломан через 22-й порт, подразумевают, что на этом сервере была запущена служба sshd, которая прослушивала 22-й порт, и злоумышленникам удалось реализовать один из известных векторов атак, например, методом брутфорса подобрать пароль администратора. Как говорится: «Дети, самый лучший пароль для администратора – это SSH-ключ» )))
Довольно часто у администраторов складывается ошибочное впечатление, что количество портов ограничивает количество входящих TCP-соединений. На самом деле тот же веб-сервер может принимать все входящие соединения на один 443-й порт, и у операционной системы не возникает никаких проблем с разбором входящих пакетов, для чего она использует дополнительно IP-адрес и порт отправителя. Таким образом, количество портов ограничивает не число соединений, а количество разных сетевых приложений, которые могут работать одновременно.
Отметим также, что правила привязки довольно гибкие, поэтому приложение может подписаться как на получение всех пакетов, поступающих на 443-й порт, так и конкретизировать, что это должны быть только TCP-пакеты или что эти пакеты должны поступать на интерфейс с конкретным IP-адресом. Поэтому в правилах межсетевого экрана для веб-приложения может быть указано требование открыть входящий порт в формате 443/TCP для конкретного IP.
Межсетевой уровень
Сегменты транспортного уровня передаются по компьютерной сети внутри пакетов межсетевого уровня, которые называются также датаграммами. Основным протоколом на этом уровне является, конечно же, протокол IP:
IP (Internet Protocol — межсетевой протокол) – обеспечивает доставку пакетов между любыми хостами сети через произвольное количество промежуточных узлов (маршрутизаторов).
Протокол не гарантирует надежной доставки до адресата, т.е. пакеты могут прийти в неправильном порядке, продублироваться, оказаться повреждёнными или вовсе потеряться по дороге. Гарантию безошибочной доставки дают некоторые протоколы более высокого уровня, например, TCP, которые используют IP в качестве транспорта.
Протокол IP стал вторым протоколом, роль которого разработчики отметили внесением его имени в общее название стека.
Дополнительно можно упомянуть протоколы:
ICMP (Internet Control Message Protocol — протокол межсетевых управляющих сообщений) — обеспечивает передачу служебных сообщений об ошибках и других исключительных ситуациях, возникших при передаче данных.
Протокол используется, например, одной из самых популярных утилит ping, которая позволяет проверить доступность узла. Технически ICMP основан на протоколе IP, т.е. каждое ICMP-сообщение инкапсулируется непосредственно в пределах одного IP-пакета.
IGMP (Internet Group Management Protocol — протокол управления группами Интернета) — используется для объединения сетевых устройств в группы, например, для организации широковещательных трансляций потокового видео или многоадресной рассылки при установке операционной системы по сети. Технически протокол IGMP основан на IP.
Для работы протокола зарезервирована сеть 224.0.0.0/4 (224.0.0.0 — 239.255.255.255), каждый адрес которой определяет одну мультикастную группу. Серверное приложение в момент своего запуска посылает в сеть уведомление, что соответствующая группа доступна, а клиенты отвечают, что они хотят присоединиться, при этом роутеры и свитчи запоминают, что за соответствующим маршрутом/портом находится клиент соответствующей мультикастной группы. Добавление новых участников и удаление отключившихся также регулируется через протокол IGMP.
Следуя той же логике инкапсуляции, датаграммы включают сегменты транспортного уровня, добавляя к ним IP-заголовок со всей необходимой метаинформацией. Среди параметров, которые передаются в заголовке датаграммы, наиболее важным является IP-адрес.
Как мы обсуждали выше, адрес IPv4 представляет собой 32-битное целое число, которое обычно представляют в виде четырех октетов, разделенных символом точки. Используя значение IP-адреса, сетевой стек выбирает из таблицы маршрутизации наиболее подходящее направление для доставки пакета и посылает его в соответствующий сетевой интерфейс. Важно понимать, что значение маски этого маршрута не включается в IP-заголовок. Эта информация остается только на узлах сети и используется ими для правильной настройки маршрутизации.
Канальный уровень
На самом нижнем уровне сетевой модели TCP/IP находится канальный уровень, где под каналом подразумевается канал связи, через который осуществляется взаимодействие устройства с компьютерной сетью.
Датаграммы передаются по компьютерной сети внутри Ethernet-пакетов, которые называют также фреймами или кадрами. Основными протоколами на канальном уровне являются:
Ethernet (ether — эфир и network — сеть) — самый распространенный протокол для передачи данных между устройствами, который использует MAC-адреса (Media Access Control) для идентификации отправителя и получателя данных.
ARP (Address Resolution Protocol — протокол определения адреса) — предназначен для определения MAC-адреса другого компьютера по известному IP-адресу.
RARP (Reverse Address Resolution Protocol — обратный протокол преобразования адресов) — предназначен для обратного отображения адресов, то есть определяет IP-адрес другого компьютера по известному MAC-адресу.
Следуя той же логике инкапсуляции, Ethernet-кадры включают датаграммы межсетевого уровня, добавляя к ним заголовок со всей необходимой метаинформацией, среди которой наиболее важным параметром является MAC-адрес.
Значение MAC-адреса представляет собой 12-разрядное шестнадцатеричное число, которое должно уникально идентифицировать сетевое устройство в пределах физического сегмента компьютерной сети. Это значение устанавливается сетевому устройству на заводе с использованием уникального префикса производителя, поэтому вероятность того, что в одной сети окажется два устройства с одним и тем же MAC-адресом, крайне мала. При необходимости MAC-адрес можно изменить в настройках сетевой карты на программном уровне.
Чтобы определить MAC-адрес устройства, которому нужно передать IP-датаграмму, компьютер отправляет в сеть широковещательный ARP-запрос. Полученные результаты записываются в заголовок Ethernet-кадра и кэшируются в ARP-таблице для повышения производительности работы сети.
К канальному уровню TCP/IP часто приписывают также физический уровень, т.к. модель TCP/IP (в отличие от OSI) не затрагивает и никак не стандартизирует аспекты физической передачи данных. А некоторые авторы так вообще добавляют к TCP/IP еще один уровень, наделяя этот стек свойствами пятиуровневой модели, что не только противоречит официальным RFC, но и создает дополнительную путаницу. Поэтому при ознакомлении с документацией, профильными статьями и учебной литературой вам следует обращать внимание на контекст, в котором авторы этих материалов излагают свои тезисы.
Протокол TCP в деталях
Продолжаем погружение. Теперь более подробно рассмотрим процесс установления соединения по протоколу транспортного уровня TCP.
Заголовок сегмента
Сегмент TCP (так называют TCP-пакеты) состоит из заголовка и данных, см. рис. 126.
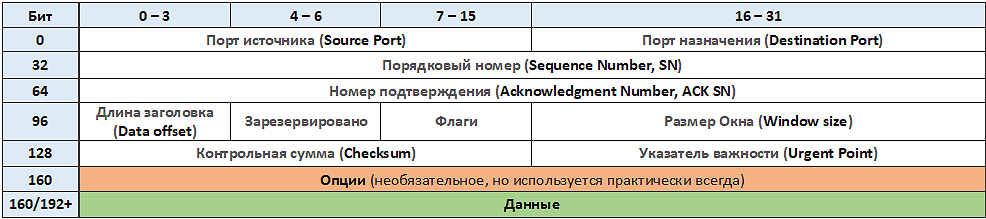
рис. 126 Структура заголовка сегмента TCP
Порт источника и назначения (по 16 бит) – поля, содержащие соответственно номер порта отправителя и получателя TCP-пакета.
Порядковый номер (32 бита) – поле, которое позволяет восстановить правильный порядок сегментов на стороне получателя. Нумерация необходима, т.к. при отправке большого объема данных для повышения эффективности протокола информация разбивается на небольшие сегменты размером 1500 байт, и нижележащие протоколы не гарантируют того, что пакеты придут к получателю в том же порядке. Размер сегментов можно регулировать, за это отвечает настройка MTU (maximum transmission unit — максимальная единица передачи).
Номер подтверждения (32 бита) – если установлен флаг ACK, то это поле содержит порядковый номер октета, который отправитель данного сегмента желает получить. Это означает, что все предыдущие октеты (с номерами от ISN+1 до ACK-1 включительно) были успешно получены.
Длина заголовка (смещение данных, 4 бита) – указывает значение длины заголовка, измеренное в 32-битовых словах. Минимальный размер составляет 20 байт (пять 32-битовых слов), а максимальный — 60 байт (пятнадцать 32-битовых слов). Длина заголовка определяет смещение полезных данных относительно начала сегмента.
Флаги (девять управляющих бит), из которых наиболее интересными являются SYN и ACK, которые используются в процедуре «рукопожатия» для установления соединения.
Размер окна (16 бит) – определяет количество байт данных (англ. payload), после передачи которых отправитель ожидает подтверждения от получателя, что данные получены. Иначе говоря, получатель пакета располагает для приёма данных буфером длиной «размер окна» байт.
Контрольная сумма (16 бит) – при расчёте контрольной суммы значение самого поля контрольной суммы принимается равным 0.
Указатель важности (16 бит) – это поле указывает порядковый номер октета, которым заканчиваются важные (urgent) данные. Поле принимается во внимание только для пакетов с установленным флагом URG.
Опции – могут применяться в некоторых случаях для расширения протокола.
Механизм работы протокола
Перед непосредственной отправкой пакетов протокол TCP (в отличии от UDP) устанавливает соединение, поэтому процесс передачи данных по протоколу TCP можно представить в трех актах: установка соединения, передача данных и завершение соединения.
Соединение TCP может находиться в одном из 11 состояний:
CLOSED – начальное состояние узла. Фактически фиктивное.
LISTEN – сервер ожидает запросы установления соединения от клиента.
SYN-SENT – клиент отправил запрос серверу на установление соединения и ожидает ответа.
SYN-RECEIVED – сервер получил запрос на соединение, отправил ответный запрос и ожидает подтверждения.
ESTABLISHED – соединение установлено, идёт передача данных.
FIN-WAIT-1 – одна из сторон (узел-1) завершает соединение путем отправки сегмента, в котором установлен флаг FIN.
CLOSE-WAIT – другая сторона (узел-2) переходит в это состояние, отправив, в свою очередь, сегмент ACK и продолжает одностороннюю передачу.
FIN-WAIT-2 – узел-1 получает ACK, продолжает чтение в ожидании получения сегмента с флагом FIN.
LAST-ACK – узел-2 заканчивает передачу и отправляет сегмент с флагом FIN.
TIME-WAIT – узел-1 получил сегмент с флагом FIN, отправил сегмент с флагом ACK и ждёт 2*MSL (максимальное временя жизни сегмента) секунд, перед окончательным закрытием соединения
CLOSING – обе стороны инициировали закрытие соединения одновременно: после отправки сегмента с флагом FIN узел-1 также получает сегмент FIN, отправляет ACK и находится в ожидании сегмента ACK (подтверждения на свой запрос о разъединении).
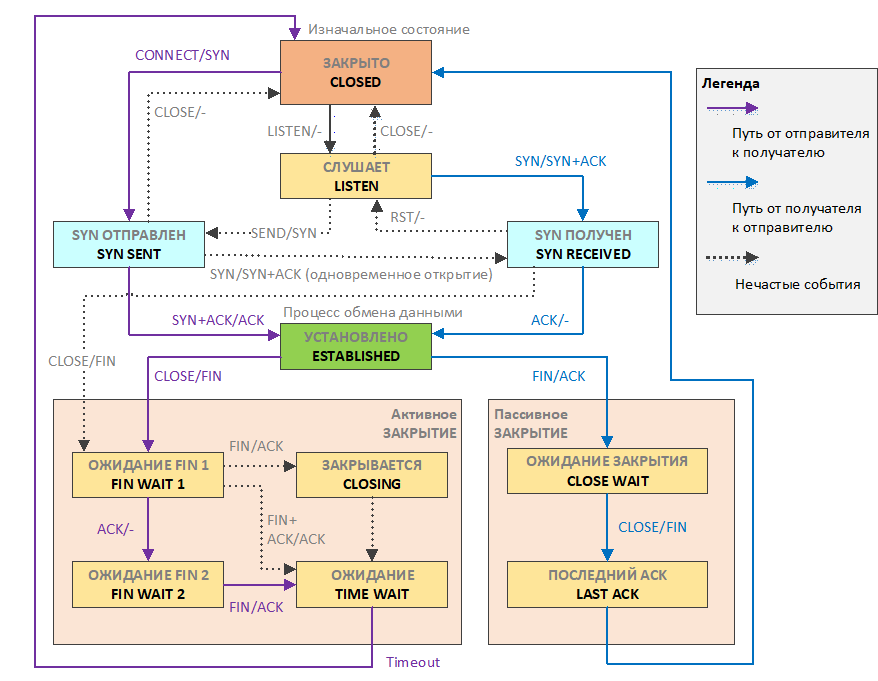
рис. 127 Схема состояний TCP
Установка утилиты wireshark для анализа сетевого трафика при TCP-соединении
Проанализируем сетевой трафик, генерируемый утилитой dig при разрешении имени astralinux.ru. Для этого воспользуемся утилитой wireshark.
Установим Wireshark и запустим её:
localadmin@astra:~$ sudo apt install wireshark
localadmin@astra:~$ sudo wireshark &
Запустим сбор трафика с интерфейса eth0:
Выполним в терминале команду dig для разрешения имени «astralinux.ru»:
localadmin@astra:~$ dig astralinux.ru @77.88.8.8 +tcp
Где:
@77.88.8.8 – DNS-сервер Яндекса.
+tcp – параметр, предписывающий команде использовать протокол TCP (по умолчанию используется UDP).
Остановим сбор трафика в окне программы wireshark и применим фильтр «tcp»:
При успешном выполнении команды в окне программы wireshark мы увидим весь процесс обмена сообщениями:
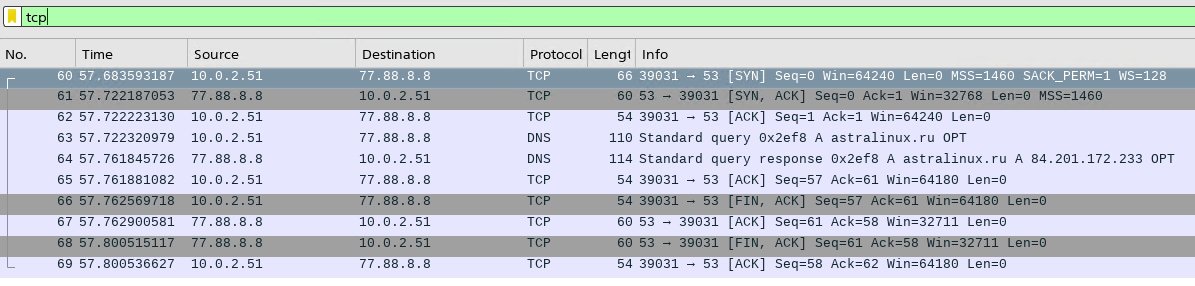
Выбрав пункт меню , можно открыть окно с графом обмена сообщениями. Выберем опцию «Limit to display filter» и тип «TCP Flows»:
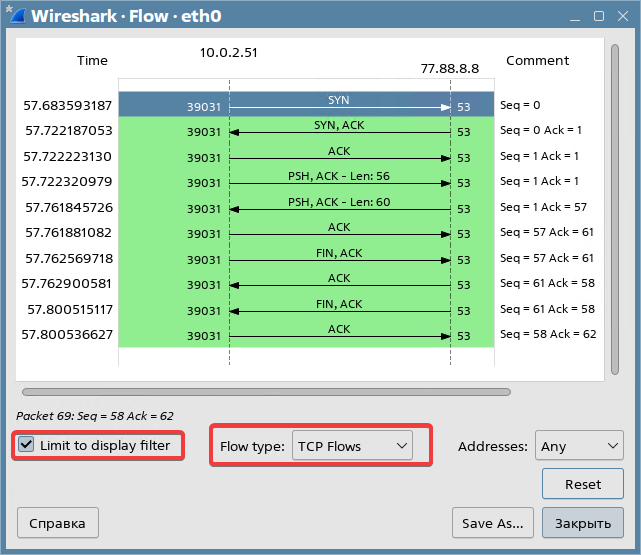
В следующих подразделах мы разберем эти сообщения, так что пока не закрывайте окно Wireshark.
Установка соединения
Процесс установки соединения называется также «рукопожатием» (англ. handshake) и проходит в три этапа:
Клиент, который намеревается установить соединение, посылает серверу сегмент с флагом SYN.
Сервер получает сегмент, запоминает номер последовательности и пытается создать сокет (буфер и управляющие структуры памяти) для обслуживания нового клиента.
В случае успеха сервер посылает клиенту сегмент с номером последовательности и флагами SYN и ACK и переходит в состояние SYN-RECEIVED.
В случае неудачи сервер посылает клиенту сегмент с флагом RST.
Если клиент получает сегмент с флагом SYN, то он запоминает номер последовательности и посылает сегмент с флагом ACK.
Если клиент одновременно получает и флаг ACK (что обычно и происходит), то он переходит в состояние ESTABLISHED.
Если клиент получает сегмент с флагом RST, то он прекращает попытки соединиться.
сли клиент не получает ответ в течение 10 секунд, то он повторяет процесс соединения заново.
Если сервер в состоянии SYN-RECEIVED получает сегмент с флагом ACK, то он переходит в состояние ESTABLISHED.
В противном случае после тайм-аута он закрывает сокет и переходит в состояние CLOSED.
Ниже приведен пример базового трехэтапного согласования:
Узел-1 клиент |
Узел-2 сервер |
||
|---|---|---|---|
1 |
CLOSED |
LISTEN |
|
2 |
SYN-SENT –> |
<SEQ=100><CTL=SYN> |
–> SYN-RECEIVED |
3 |
ESTABLISHED <– |
<SEQ=300><ACK=101><CTL=SYN,ACK> |
<– SYN-RECEIVED |
Узел 1 передает сегмент с флагом SYN и номером последовательности 100.
Узел 2 передает в ответ сегмент SYN с номером последовательности 300 и подтверждением ACK о принятом SYN (SEQ 101).
Узел 1 отвечает пустым сегментом с подтверждением ACK о принятом SYN (SEQ 301).
Номер последовательности SEQ – это счетчик, указывающий, сколько данных (в байтах) было отправлено в текущем сеансе TCP. Номер подтверждения ACK – это подтверждение о полученных данных и готовности к следующему сегменту.
С номером подтверждения ACK не все так просто. При передаче информации номер ACK равен сумме номера полученной последовательности и длины её сегмента TCP: ACKобмен сообщениями = SEQ + LEN. Однако при установке и завершении соединения этот номер будет инкрементироваться на единицу: ACKустановка/завершение соединения = SEQ + LEN + 1 (длина при этом равна 0).
В нашем примере с DNS-запросом обратим внимание на первые 3 итерации – это и есть процесс «рукопожатия» в TCP:


Клиент отправляет серверу сообщение c флагом SYN и номером последовательности 0 (SEQ=0).
Сервер отвечает клиенту сообщением с флагами SYN, ACK, номером последовательности 0 (SEQ=0) и подтверждением 1 (ACK=1).
Клиент отвечает серверу сообщением с флагом ACK, номером последовательности 1 (SEQ=1) и подтверждением 1 (ACK=1).
Примечание
По умолчанию Wireshark преобразует все порядковые номера и номера подтверждений в относительные номера. Это означает, что все номера SEQ и ACK всегда начинаются с 0 для первого пакета в каждой TCP-сессии.
Процесс передачи данных
При обмене данными приёмник использует номер последовательности, содержащийся в получаемых сегментах, для восстановления их исходного порядка. Приёмник уведомляет передающую сторону о номере последовательности, до которой он успешно получил данные, включая его в поле «номер подтверждения».
Если полученный сегмент содержит номер последовательности больший, чем ожидаемый, то данные из сегмента буферизируются, но номер подтверждённой последовательности не изменяется. Если впоследствии будет принят сегмент, относящийся к ожидаемому номеру последовательности, то порядок данных будет автоматически восстановлен исходя из номеров последовательностей в сегментах.
Поле «окно» позволяет принимающей стороне управлять интенсивностью потока данных. Сторона отправителя не будет посылать данных больше, чем указано в этом поле.
С помощью флага PSH передающая сторона может затребовать принять данные, не буферизуя их. Это «проталкивание» используется, например, в интерактивных приложениях.
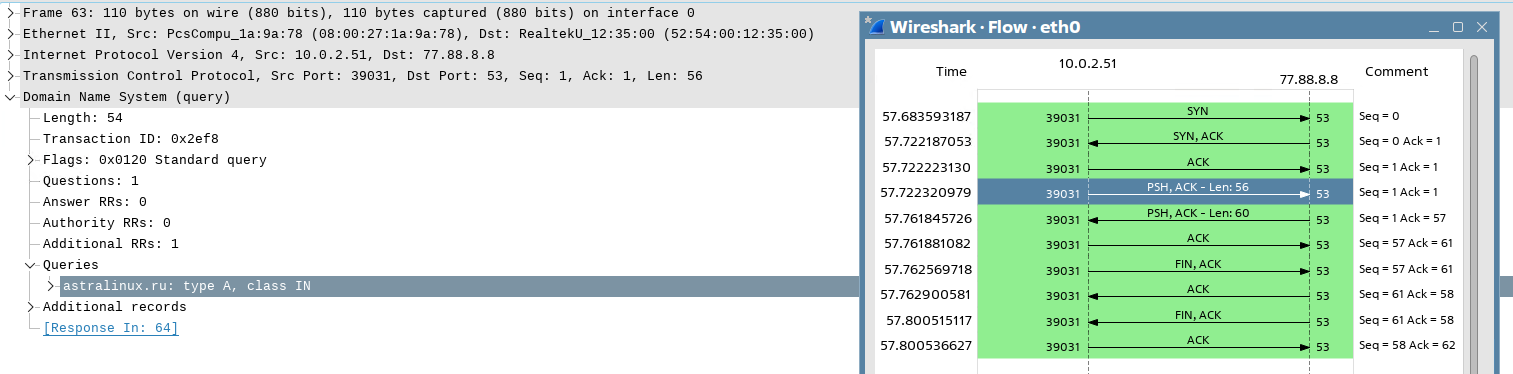
Вернемся в окно программы Wireshark и рассмотрим обмен сообщениями по протоколу DNS:
Клиент отправляет серверу DNS-запрос на разрешения имени «astralinux.ru». Как видим, тут как раз используется флаг PSH:
Сервер DNS отправляет клиенту ответ с найденным IP-адресом:
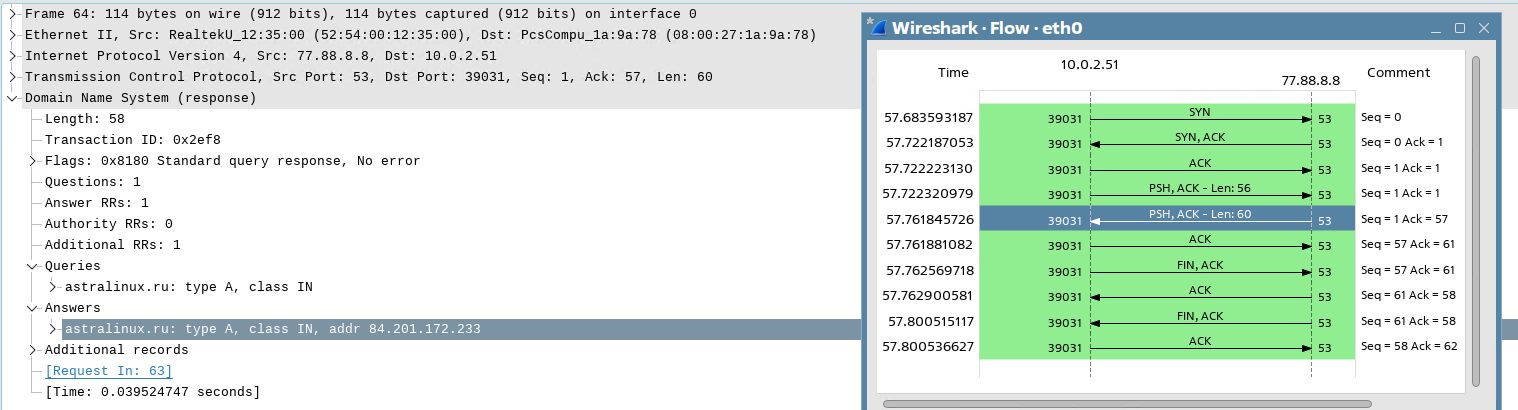
Обратите внимание, что номер подтверждения в этом случае будет ACK=57, так как это подтверждение на сообщение с номером последовательности SEQ=1 и длиной LEN=56.
Следующим сообщением с флагом ACK, номером последовательности 57 (SEQ=57) и подтверждением 61 (ACK=61) клиент уведомляет сервер, что он получил и принял отправленный ему пакет.
В разделе «Transmission Control Protocol» можно посмотреть параметры передачи сообщений, в том числе и вышеупомянутое поле «окно» и флаги:
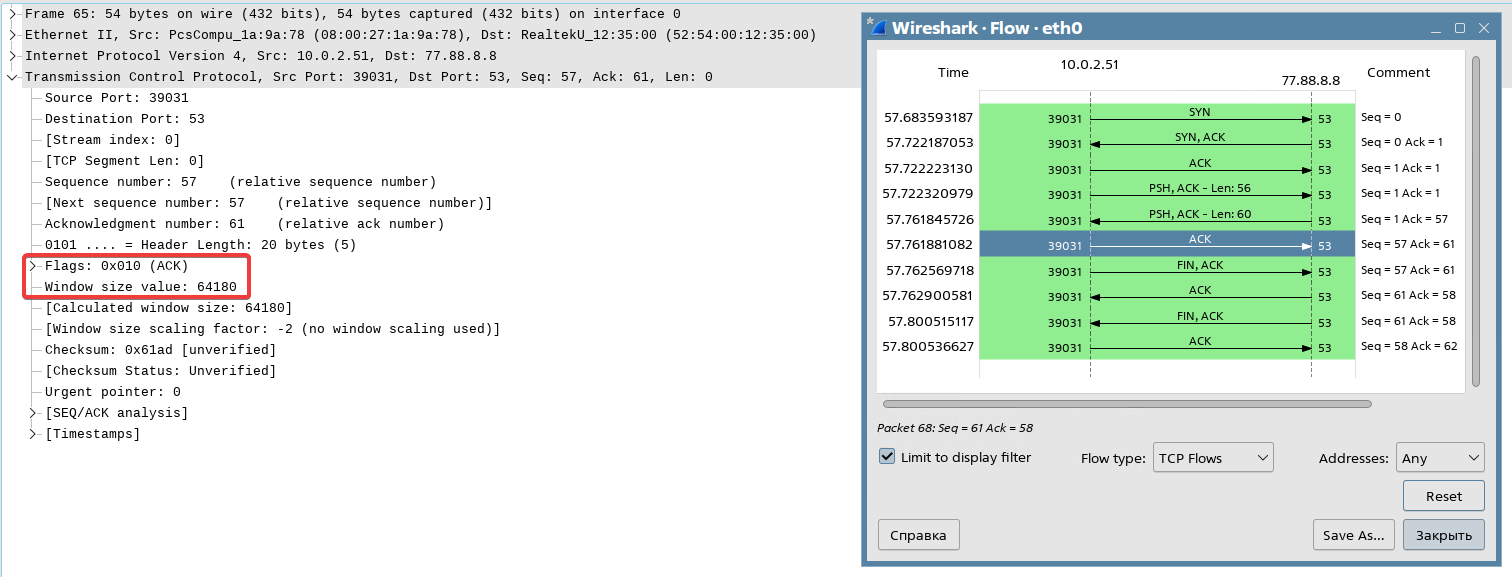
Завершение соединения
Завершение соединения можно рассмотреть в четыре этапа:
Узел-1 клиент |
Узел-2 сервер |
||||
|---|---|---|---|---|---|
ESTABLISHED |
ESTABLISHED |
||||
(Close) FIN-WAIT-1 |
–> |
<SEQ=100><ACK=300><CTL=FIN,ACK> |
–> |
CLOSE-WAIT |
|
FIN-WAIT-2 |
<– |
<SEQ=300><ACK=101><CTL=ACK> |
<– |
CLOSE-WAIT |
|
(Close) TIME-WAIT |
<– |
<SEQ=300><ACK=101><CTL=FIN,ACK> |
<– |
LAST-ACK |
|
TIME-WAIT |
–> |
<SEQ=101><ACK=301><CTL=ACK> |
–> |
CLOSED |
|
(2 MSL) CLOSED |
При завершении соединения клиент посылает серверу сообщение с флагами FIN и ACK, что означает, что клиент получил все необходимые ему данные и хочет закрыть соединение (SEQ=100, ACK=300).
В ответ сервер уведомляет клиента (ACK), что принял сообщение (SEQ=300, ACK=101).
В случае, если у сервера больше нет данных для клиента, он отправит ему сообщение с флагами FIN и ACK (SEQ=300, ACK=101).
Процесс закрытия сессии завершается отправкой клиентом серверу уведомления (ACK), что он принял сообщение (SEQ=101, ACK=301).
В нашем примере с DNS-запросом в Wireshark это выглядит следующим образом:


Протокол IP в деталях
Как мы помним, протокол объединяет сегменты сети (не путать с TCP-сегментами), обеспечивая доставку данных между любыми узлами сети через произвольное число промежуточных узлов (маршрутизаторов).
При доставке IP-пакета он проходит через разные каналы доставки. Возможно возникновение ситуации, когда размер пакета превысит возможности узла системы связи. В этом случае протокол предусматривает возможность дробления пакета, что называется IP-фрагментацией. В протоколе предусмотрена возможность запрета фрагментации конкретного пакета. Если такой пакет нельзя передать через сегмент связи целиком, то он уничтожается, а отправителю направляется ICMP-сообщение о проблеме.
Сейчас используются две актуальные версии протокола:
IPv4 — предусматривает использование 32-битных адресов, которых, как оказалось, не так уж и много, в связи с чем приходится придумывать разные ухищрения, такие как трансляция адресов NAT. Но этот протокол еще на долгие годы будет оставаться основной рабочей лошадкой.
IPv6 — разработан для решения проблемы нехватки адресов IPv4 и предусматривает использование адресного пространства емкостью 2128, что очень-очень много, но это сделано для использования иерархии адресов в целях упрощения маршрутизации.
Адрес в IPv6 представлен восемью четырехзначными шестнадцатеричными числами, разделенными двоеточиями, например, 2001:0db8:11a3:09d7:1f34:8a2e:07a0:765d, и это, пожалуй, все, что мы хотели бы рассказать.
Мы уже затрагивали вопрос того, что адреса IPv4 могут быть публичными (белыми) и частными, но добавим немного дополнительных деталей.
Частный IP-адрес (англ. private IP address), называемый также внутренним, внутрисетевым или локальным — это IP-адрес, принадлежащий к специальному диапазону, не используемому в сети Интернет. Такие адреса предназначены для применения в локальных сетях, и их распределение контролируется только внутри предприятия.
Для того чтобы компьютеры, использующие локальные адреса, могли выйти в Интернет, используется технология трансляции адресов NAT (Network Address Translation — преобразование сетевых адресов). Публичный адрес назначается только NAT-шлюзу, который принимает запросы на пересылку пакетов от клиентов локальной сети и подставляет в них свой собственный адрес в качестве IP-адреса получателя. При получении ответа NAT-шлюз выполняет обратное действие, чтобы клиенты считали, что они взаимодействуют с сервером напрямую. Таким образом, все пользователи предприятия ходят в сеть под одним и тем же белым IP-адресом.
Существуют следующие сети частных адресов IPv4:
Сеть 192.168.0.0/16 — включает всего 65к адресов, поэтому считается сетью для домашнего пользования. Эти адреса обычно используют Интернет-провайдеры для физических лиц, и они довольно часто назначены в простеньких роутерах по умолчанию.
Сеть 172.16.0.0/12 — включает порядка 1 млн. адресов, поэтому может использоваться в школах, университетах и на предприятиях малого бизнеса.
Сеть 10.0.0.0/8 — включает порядка 16 млн. адресов, поэтому подходит для построения сетей любого масштаба вплоть до предприятий крупного бизнеса.
Сеть 100.64.0.0/10 — рекомендована для использования провайдерами в качестве адресов CGN (Carrier-Grade NAT). Эта технология отличается от обычного NAT тем, что один публичный IP-адрес может использоваться несколькими маршрутизаторами клиента.
Сеть 169.254.0.0/16 — включает 65к link-local адресов, которые предназначены для коммуникаций только в пределах одного физического сегмента сети, т.е. маршрутизаторы не пересылают пакеты, если в качестве источника или приемника указан link-local адрес. Раньше эти адреса могли быть использованы в небольших локальных сетях без выхода в Интернет. Серверам они назначались вручную, а рабочие станции выбирали себе адрес автоматически, если не получали ответ от DHCP-сервера. В Microsoft такой способ настройки называли APIPA (англ. Automatic Private IP Addressing — автоматическая адресация внутри локальной сети).
В настоящее время эта сеть практически не используется, и мы сталкиваемся с этими адресами только в том случае, если сервер DHCP оказался недоступен. Но если вам потребуется создать ну очень защищенный периметр без возможности выхода в Интернет на аппаратном уровне, теперь вы знаете, как это сделать )))
Сеть 127.0.0.0/8 — адреса локальной петлей, и включает порядка 16 млн. адресов. Они используется для организации межпроцессного взаимодействия между приложениями, которые запущены внутри одной операционной системы.
Заголовок датаграммы
Пакет IP — это форматированный блок информации, передаваемый по компьютерной сети, структура которого определена протоколом IP, см. рис. 128.
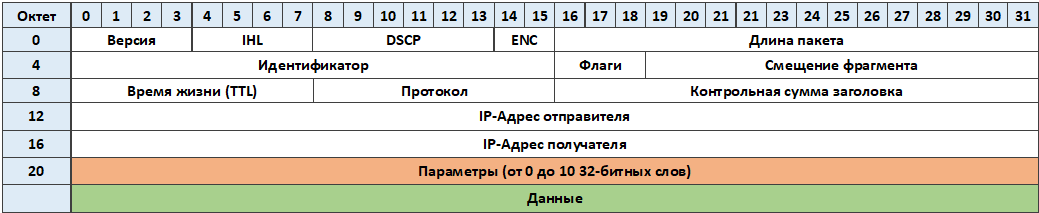
рис. 128 Структура IP-пакета
Версия — для IPv4 значение поля должно быть равно 4.
IHL (Internet Header Length) длина заголовка IP-пакета в 32-битных словах (dword). Именно это поле указывает на начало блока данных (англ. payload — полезный груз) в пакете. Минимальное корректное значение для этого поля равно 5.
DSCP (Differentiated Services Code Point, точка кода дифференцированных услуг) – элемент архитектуры компьютерных сетей, описывающий простой масштабируемый механизм классификации, управления трафиком и обеспечения качества обслуживания.
ECN (Explicit Congestion Notification, явное уведомление о перегруженности) – расширение протокола IP, описанное в RFC 3168. ECN позволяет обеим сторонам в сети узнавать о возникновении затора на маршруте к заданному хосту или сети без отбрасывания пакетов.
Длина пакета (Total Length) — длина пакета в октетах, включая заголовок и данные. Минимальное корректное значение для этого поля равно 20, максимальное — 65 535.
Идентификатор (Identification) — значение, назначаемое отправителем пакета и предназначенное для определения корректной последовательности фрагментов при сборке пакета. Для фрагментированного пакета все фрагменты имеют одинаковый идентификатор.
Три бита флагов — Первый бит должен быть всегда равен нулю, второй бит DF (don’t fragment) определяет возможность фрагментации пакета и третий бит MF (more fragments) показывает, не является ли этот пакет последним в цепочке пакетов.
Смещение фрагмента (Fragment Offset) — значение, определяющее позицию фрагмента в потоке данных. Смещение задается количеством восьмибайтовых блоков, поэтому это значение требует умножения на 8 для перевода в байты.
Время жизни (TTL, time to live) — число маршрутизаторов, через которые может пройти этот пакет, прежде чем будет отброшен. При прохождении через маршрутизатор это число уменьшается на единицу. Если значение этого поля равно нулю, то пакет должен быть отброшен и отправителю будет послано сообщение Time Exceeded (ICMP тип 11 код 0).
Протокол — идентификатор сетевого протокола следующего уровня указывает, данные какого протокола содержит пакет, например, TCP, UDP, или ICMP (см. IANA protocol numbers и RFC 1700).
Контрольная сумма заголовка (Header Checksum) — вычисляется по правилам RFC 1071.
Маршрутизация трафика
Маршрутизация — это одна из наиболее важных функций протокола IP. Она позволяет перенаправлять IP-пакеты между разными сетями, то есть управлять процессом объединения различных сетей в маршруты для прохождения пакетов от одного узла к другому.
Если сеть подключена к маршрутизатору непосредственно, он уже знает, как направить пакет в эту сеть. Если же сеть напрямую не подключена, администраторы должны настроить маршруты вручную (статическая маршрутизация) или включить динамическую маршрутизацию.
Динамическая маршрутизация — это протокол, определяющий взаимодействие маршрутизаторов между собой для автоматического распространения информации о маршрутах. Если на каком-то из маршрутизаторов в сети произойдет изменение в таблице маршрутов, он сможет по протоколу динамической маршрутизации автоматически проинформировать об этих изменениях своих соседей, а те передадут информацию дальше по цепочке. На небольших предприятиях используют в основном статическую маршрутизацию.
Рассмотрим процесс маршрутизации на примере проверки доступности узла с помощью утилиты ping, которая под капотом использует протокол ICMP. Все использованные в примере сети, IP и MAC-адреса являются вымышленными и любое совпадение с реальными адресами являются чистой случайностью )))
Предположим, у нас есть 2 узла с IP-адресами 192.168.10.2/24 и 192.168.20.2/24 соединённые кабелем с маршрутизатором, у которого один интерфейс подключен к сети 192.168.10.0/24, и его IP-адрес 192.168.10.1/24, а другой интерфейс подключён к сети 192.168.20.0/24 и его IP-адрес 192.168.20.1/24. На узлах 1 и 2 настроены шлюзы по умолчанию 192.168.10.1 и 192.168.20.1 соответственно.
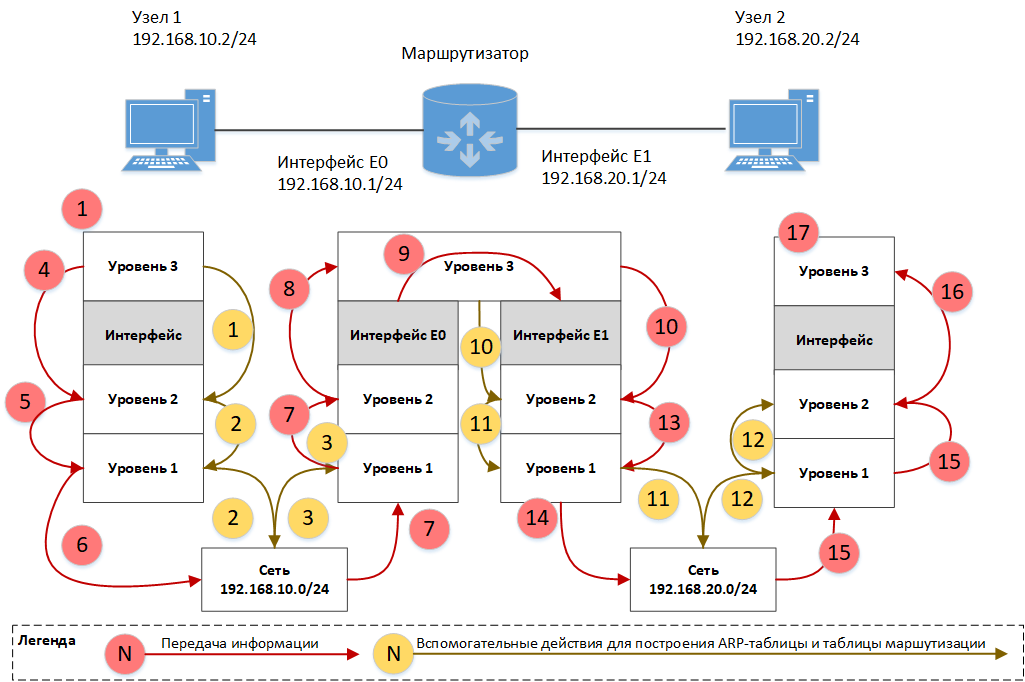
рис. 129 Схема маршрутизации запроса ICMP на узел, находящийся в другой подсети
В таблице ниже приведен процесс маршрутизации ICMP пакета.
Шаг |
Узел |
Интерфейс |
Действия |
|---|---|---|---|
Шаг 1 |
Узел 1 |
192.168.10.2/24 |
ping 192.168.20.2.
|
Шаг 2 |
Узел 1 |
192.168.10.2/24 |
Узел 1 отправляет широковещательный ARP-запрос в сеть 192.168.10.0:
|
Шаг 3 |
Маршрутизатор |
192.168.10.1/24 |
Интерфейс E0 отвечает узлу 1 своим MAC-адресом:
|
Шаг 4 |
Узел 1 |
192.168.10.2/24 |
Узел 1 получил ответ от маршрутизатора, все необходимые данные для передачи пакета собраны. IP-пакет передается от сетевого к канальному уровню. |
Шаг 5 |
Узел 1 |
192.168.10.2/24 |
|
Шаг 6 |
Узел 1 > Маршрутизатор |
192.168.10.2/24 |
|
Шаг 7 |
Маршрутизатор |
192.168.10.1/24 |
|
Шаг 8 |
Маршрутизатор |
192.168.10.1/24 |
|
Шаг 9 |
Маршрутизатор |
192.168.10.1/24 > 192.168.20.1/24 |
|
Шаг 10 |
Маршрутизатор |
192.168.20.1/24 |
|
Шаг 11 |
Маршрутизатор |
192.168.20.1/24 |
Маршрутизатор отправляет широковещательный ARP-запрос в сеть 192.168.20.0:
|
Шаг 12 |
Узел 2 |
192.168.20.2/24 |
Интерфейс узла 2 отвечает маршрутизатору своим MAC-адресом:
|
Шаг 13 |
Маршрутизатор |
192.168.20.1/24 |
|
Шаг 14 |
Маршрутизатор > Узел 2 |
192.168.20.1/24 |
|
Шаг 15 |
Узел 2 |
192.168.20.2/24 |
|
Шаг 16 |
Узел 2 |
192.168.20.2/24 |
|
Шаг 17 |
Узел 2 |
192.168.20.2/24 |
|
Процесс передачи ICMP пакета запускается в обратную сторону с той лишь разницей, что в ARP-кэшах устройств уже присутствуют все необходимые данные и выполнять ARP-запросы устройствам в этом случае не придется.
Если бы сети узла 1 и узла 2 не были бы «соседями» и на пути маршрута между ними были несколько сетей и маршрутизаторов, то логика прохождения пакетов все равно осталась бы прежней, увеличилось бы только количество промежуточных устройств и шагов обработки пакетов.
Работа сетевого стека в Linux
В современных операционных системах (таких как Linux, Windows, MacOS и далее по списку) основная часть стека сетевых протоколов реализована внутри ядра вплоть до транспортного уровня включительно. Работа в пространстве ядра позволяет получить прямой доступ к оборудованию и снизить накладные расходы на переключение контекста, что обеспечивает безопасную работу с сетевыми данными на высоких скоростях.
Функционирует это следующим образом: ядро Linux получает прерывания от сетевого адаптера и обрабатывает пакеты из очереди, пропуская их через канальный (Ethernet), сетевой (IP) и транспортный (TCP, UDP) уровни протоколов, перекладывая информацию в конечном итоге в буферы сокетов, откуда ее могут вычитать приложения с помощью стандартных системных вызовов, см. рис. 130.
К сетевым пакетам дополнительно применяются правила маршрутизации и фильтрации подсистемы Netfilter, которая позволяет подключать дополнительные модули ядра для управления сетевыми пакетами. Настройка таблиц маршрутизации выполняется, например, с помощью клиентских утилит ip и iproute2, а правила фильтрации и трансляции адресов можно настроить с помощью утилиты nft (ранее использовалась утилита iptables).
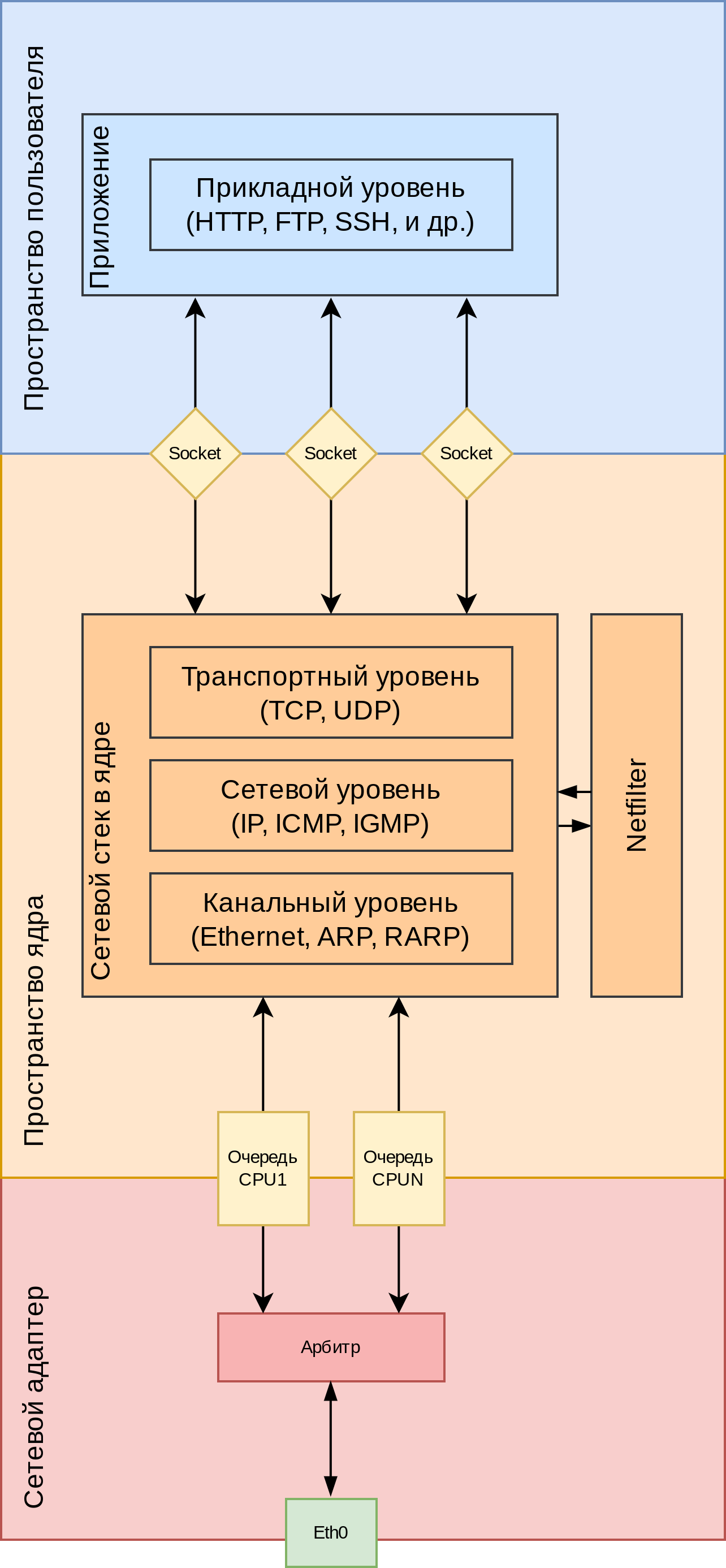
рис. 130 Архитектура сетевого взаимодействия в системе Linux
Но чтобы не заниматься настройкой правил nftables на низком уровне, вы можете воспользоваться простым межсетевым экраном UFW (англ. Uncomplicated Firewall), для которого есть даже графический интерфейс GUFW, сопоставимый по функциональным возможностям с Windows Defender Firewall.
Кроме правил фильтрации, определенных пользователем, есть еще правила отбрасывания пакетов, предусмотренные протоколами. Например, если пакеты будут содержать IP-адрес, не принадлежащий устройству, они будут отброшены сетевым стеком ядра операционной системы, а если в них будет MAC-адрес, не соответствующий тому, что настроен в адаптере, то они даже не дойдут до ядра, т.к. их срежет сетевой адаптер (если только на нем не включен «неразборчивый режим»).
Подобных оптимизаций в работе сетевого стека как на аппаратном, так и на программном уровне реализовано уже бессчетное количество, и они будут появляться дальше, так как требования бизнеса в части использования сетевых сервисов будут только расти. Но можно с уверенностью сказать, что сетевой стек Linux уже давно является зрелой технологией, способной обеспечить работу не только серверов, но и специализированных сетевых устройств.
Ядро Linux выбирают многие производители сетевого оборудования, например, D-Link (OpenWrt), MikroTik (RouterOS) и даже такие лидеры, как Cisco (IOS XE, IOS XR). Однако важна не только технология, но и умение ее настраивать. Поэтому продолжаем погружаться в технические детали.
Подготовка стека к работе
Чтобы на компьютере можно было использовать сетевой стек, сначала его нужно инициировать, поэтому в момент загрузки системы происходит следующее:
Определяется модель сетевого адаптера и загружается соответствующий драйвер.
Драйверу выделяется оперативная память для DMA (англ. direct memory access — прямой доступ к памяти), далее мы расскажем об этом подробнее.
Создается поток для программных прерываний по одному на каждом из ЦПУ.
В ядре создается обработчик программных прерываний.
Создаются очереди для приема и передачи пакетов.
На каждом из ЦПУ для NAPI (англ. New API — новый API) создается список опроса (англ. pool list), далее мы расскажем об этом подробнее.
После загрузки операционной системы требуется включить сетевой интерфейс в ядре. Сделать это можно вручную с помощью утилит ip и ifconfig или автоматически, используя один из следующих пакетов: ifupdown, NetworkManager, systemd.
Временное изменение настроек
Если вам нужно временно внести изменения в настройки соединений, вы можете воспользоваться командой ip.
Команда ip link show покажет краткую информацию о соединениях:
localadmin@astra:~$ ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 08:00:27:19:4a:3a brd ff:ff:ff:ff:ff:ff
Команда ip address или просто ip a выведет основную информацию обо всех интерфейсах:
localadmin@astra:~$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 08:00:27:19:4a:3a brd ff:ff:ff:ff:ff:ff
inet 10.0.2.15/24 brd 10.0.2.255 scope global dynamic eth0
valid_lft 85957sec preferred_lft 85957sec
inet6 fe80::a00:27ff:fe19:4a3a/64 scope link
valid_lft forever preferred_lft forever
Для временного изменения настроек интерфейса, например, для добавления еще одного IP-адреса с маской подсети можно воспользоваться командой sudo ip address add 10.0.2.16/24 dev eth0:
localadmin@astra:~$ sudo ip address add 10.0.2.16/24 dev eth0
localadmin@astra:~$ ip address show dev eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 08:00:27:19:4a:3a brd ff:ff:ff:ff:ff:ff
inet 10.0.2.15/24 brd 10.0.2.255 scope global dynamic eth0
valid_lft 85391sec preferred_lft 85391sec
inet 10.0.2.16/24 scope global secondary eth0
valid_lft forever preferred_lft forever
inet6 fe80::a00:27ff:fe19:4a3a/64 scope link
valid_lft forever preferred_lft forever
Удалим IP-адрес вместе с маской командой sudo ip address del 10.0.2.16/24 dev eth0:
localadmin@astra:~$ sudo ip address del 10.0.2.16/24 dev eth0
Выключим и включим интерфейс eth0 командой sudo ip link set eth0 down && sudo ip link set eth0 up:
localadmin@astra:~$ sudo ip link set eth0 down && sudo ip link set eth0 up
Перезагрузим службу Networking командой sudo systemctl restart networking.service:
localadmin@astra:~$ sudo systemctl restart networking.service
Постоянное изменение настроек с помощью ifupdown
Пакет ifupdown (англ. interface up/down — включение/выключение интерфейса) — это проверенное временем традиционное решение для управления сетью, которое до сих пор используется во многих дистрибутивах на базе Linux.
Автоматическая настройка сети выполняется службой networking.service в соответствии с настройками из файла /etc/network/interfaces. Для конфигурирования интерфейсов внутри ядра служба использует утилиты ifup/ifdown, которые являются обертками поверх утилиты ifconfig. Каждый раз при включении/выключении службы она делает ifup / ifdown всех интерфейсов, отмеченных опцией auto.
Для автоматического получения IP-адреса служба networking использует клиент isc-dhcp-client. Для удобства управления настройками преобразования доменных имен дополнительно может устанавливаться пакет resolvconf. В этом случае настройки можно будет привязать к интерфейсам непосредственно в конфигурационном файле interfaces.
В системе Astra Linux пакет ifupdown устанавливается по умолчанию и может использоваться на серверах для настройки интерфейсов, имеющих постоянное подключение к компьютерной сети.
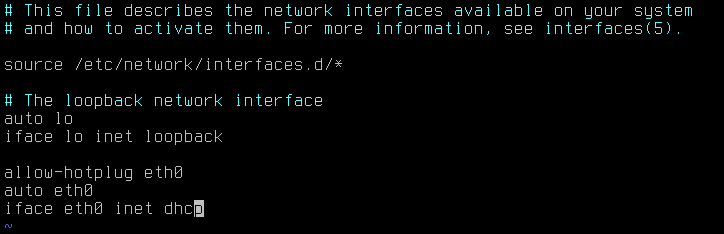
Файл /etc/network/interfaces используется командами ifup и ifdown для конфигурирования сетевых интерфейсов:
localadmin@astra:~$ cat /etc/network/interfaces
source /etc/network/interfaces.d/*
auto lo
iface lo inet loopback
allow-hotplug eth0
auto eth0
iface eth0 inet static
address 10.0.1.11
netmask 255.255.255.0
gateway 10.0.1.1
Комментарии по использованным инструкциям:
allow-hotplug eth0 — указывает, что нужно выполнять автоматический перезапуск интерфейса при его падении.
auto eth0 — строка, начинающаяся со слова «auto», задает интерфейс, который должен подниматься при вызове команды
ifup -a, которая вызывается автоматически при запуске службы networking.iface eth0 inet static — строка со словом «iface» начинает группу строк, отвечающих за настройку указанного интерфейса:
inet или inet6 — указывает, какой протокол будет использоваться (IPv4 или IPv6).
static или dhcp — указывает способ назначения настроек (вручную или динамически).
address, netmask, gateway — задают IP-адрес, маску и шлюз по умолчанию для интерфейса, указанного в предшествующей ей строке «iface», если для него выбран способ назначения настроек «static».
Если вам требуется переопределить значение MAC-адреса, то новое значение можно задать строкой hwaddress ether 00:11:22:33:44:55
Внесем изменения в файл /etc/network/interfaces для настройки сетевого интерфейса eth0 через службу networking.
Сохраним файл и перезапустим службу networking.service sudo systemctl restart networking.service. Если настройки были внесены корректно, то запуск службы пройдет без ошибок. Проверим её статус командой sudo systemctl status networking.service.
localadmin@astra:~$ sudo systemctl restart networking.service
localadmin@astra:~$ sudo systemctl status networking.service
O networking.service - Raise network interfaces
Loaded: loaded (/lib/systemd/system/networking.service; enabled; vendor preset: enabled
Active: active (exited) since Wed 2023-09-13 20:12:43 MSK; 16s ago
Docs: man:interfaces(5)
Process: 24569 ExecStart=/sbin/ifup -a --read-environment (code=exited, status=0/SUCCESS
Main PID: 24569 (code=exited, status=0/SUCCESS)
Tasks: 2 (limit: 2255)
Memory: 5.7M
CPU: 207ms
CGroup: /system.slice/networking.service
└─24589 /sbin/dhclient -4 -v -i -pf /run/dhclient.eth0.pid -lf /var/lib/dhcp/dh
сен 13 20:12:43 astra dhclient[24589]: Sending on Socket/fallback
сен 13 20:12:43 astra dhclient[24589]: Created duid "\\000\\001\\000\\001,...
сен 13 20:12:43 astra dhclient[24589]: DHCPDISCOVER on eth0 to 255.255.255.255 port 67 int
сен 13 20:12:43 astra dhclient[24589]: DHCPOFFER of 10.0.2.15 from 10.0.2.2
сен 13 20:12:43 astra dhclient[24589]: DHCPREQUEST for 10.0.2.15 on eth0 to 255.255.255.25
сен 13 20:12:43 astra dhclient[24589]: DHCPACK of 10.0.2.15 from 10.0.2.2
сен 13 20:12:43 astra ifup[24569]: RTNETLINK answers: File exists
сен 13 20:12:43 astra dhclient[24589]: bound to 10.0.2.15 -- renewal in 39567 seconds.
сен 13 20:12:43 astra ifup[24569]: bound to 10.0.2.15 -- renewal in 39567 seconds.
сен 13 20:12:43 astra systemd[1]: Started Raise network interfaces.
Не забудьте до перезапуска службы networking отключить проводное соединение в службе NetworkManager, а лучше отключить и замаскировать эту службу полностью:
localadmin@astra:~$ ls /etc/network/interfaces.d/
localadmin@astra:~$ sudo systemctl stop NetworkManager
localadmin@astra:~$ sudo systemctl disable NetworkManager
Removed /etc/systemd/system/dbus-org.freedesktop.nm-dispatcher.service.
Removed /etc/systemd/system/multi-user.target.wants/NetworkManager.service.
Removed /etc/systemd/system/network-online.target.wants/NetworkManager-wait-online.service.
localadmin@astra:~$ sudo systemctl mask NetworkManager
Created symlink /etc/systemd/system/NetworkManager.service → /dev/null.
Теперь апплет NetworkManager не активен и не показывает соединения:
рис. 131 Состояние апплета «выключено»
Постоянное изменение настроек с помощью NetworkManager
Служба NetworkManager — это современный высокоуровневый инструмент для управления сетевыми подключениями, который использует libudev и другие службы ядра Linux для автоматической перенастройки сетевых интерфейсов при перемещении портативных устройств между разными сетями. NetworkManager позволяет работать как с проводными, так и беспроводными сетевыми интерфейсами и некоторыми типами VPN-соединений.
Пакет network-manager состоит из одноименной службы, доступ к которой осуществляется по шине dbus (права суперпользователя не требуются), и ряда клиентских приложений, таких как:
nmcli — командный интерфейс
nmtui — псевдографический интерфейс
nm-applet — графический интерфейс, который по функциональности не уступает приложению «Свойства сетевого подключения» от Windows.
Для автоматического получения IP-адреса служба NetworkManager по умолчанию использует свой собственный DHCP-клиент, но при необходимости ее можно переориентировать на использование других клиентов.
Служба NetworkManager автоматически управляет также содержимым файла /etc/resolv.conf, записывая туда значение, назначенное интерфейсу или полученное от DHCP-сервера.
localadmin@astra:~$ cat /etc/resolv.conf
# Generated by NetworkManager
nameserver 77.88.8.8
При установке Astra Linux с графической оболочкой Fly пакет network-manager будет инсталлирован автоматически. На серверах со статичными настройками сети это может показаться излишним, и вы захотите сэкономить пару десятков мегабайт оперативной памяти, но предоставляемые этим пакетом удобства настолько значительны, что RHEL рекомендует использовать NetworkManager в том числе и на серверах.
Конфигурационный файл NetworkManager.conf
Настройки NetworkManager задаются в файле /etc/NetworkManager/NetworkManager.conf.
[main]
plugins=ifupdown,keyfile
[ifupdown]
managed=false
На сервере Astra Linux с графическим интерфейсом все сетевые интерфейсы по умолчанию находятся под управлением NetworkManager за исключением lo – интерфейса обратной петли. Это обеспечивается параметром «managed=false» в секции «[ifupdown]», запрещающей управлять интерфейсами, которые находятся под управлением службы Networking.
localadmin@astra:~$ cat /etc/network/interfaces
# This file describes the network interfaces available on your system
# and how to activate them. For more information, see interfaces(5).
source /etc/network/interfaces.d/*
# The loopback network interface
auto lo
iface lo inet loopback
Утилита командной строки Nmcli
Утилита nmcli (англ. Network Manager Command Line Interface) позволяет настраивать NetworkManager из командной строки. Синтаксис этой утилиты:
$ nmcli <опции> <раздел> <действия>
Всего существуют восемь разделов со своими наборами команд (действиями):
help – выдает справку о командах ncmcli и их использовании.
general – возвращает статус NetworkManager и глобальную конфигурацию.
networking – содержит команды для запроса состояния сетевого подключения и включения/отключения подключений.
radio – содержит команды для запроса состояния подключения к сети WiFi и включения/отключения подключений.
monitor – содержит команды для мониторинга активности NetworkManager и наблюдения за изменениями состояния сетевых подключений.
connection – содержит команды для управления сетевыми интерфейсами, для добавления новых соединений и удаления существующих.
device – используется в основном для изменения параметров, связанных с устройствами (например, имени интерфейса) или для подключения устройств с использованием существующего соединения.
secret – регистрирует nmcli в качестве «секретного агента» NetworkManager, который прослушивает тайные сообщения. Эта секция используется редко, потому что nmcli при подключении к сетям по умолчанию работает именно так.
Посмотреть статус NetworkManager можно командой nmcli general.
localadmin@astra:~$ nmcli general
STATE CONNECTIVITY WIFI-HW WIFI WWAN-HW WWAN
подключено полностью включен включен включен включен
Посмотреть сводную информацию по соединению можно вывести командой nmcli device show.
localadmin@astra:~$ nmcli connection show
NAME UUID TYPE DEVICE
Проводное соединение 1 26c78985-a471-3663-98bb-9afbf978d59c ethernet eth0
Подробные настройки интерфейса можно командой nmcli device show eth0.
localadmin@astra:~$ nmcli device show eth0
GENERAL.DEVICE: eth0
GENERAL.TYPE: ethernet
GENERAL.HWADDR: 08:00:27:19:4A:3A
GENERAL.MTU: 1500
GENERAL.STATE: 100 (подключено)
GENERAL.CONNECTION: Проводное соединение 1
GENERAL.CON-PATH: /org/freedesktop/NetworkManager/ActiveConnection/1
WIRED-PROPERTIES.CARRIER: вкл.
IP4.ADDRESS[1]: 10.0.2.15/24
IP4.GATEWAY: 10.0.2.2
IP4.ROUTE[1]: dst = 0.0.0.0/0, nh = 10.0.2.2, mt = 100
IP4.ROUTE[2]: dst = 10.0.2.0/24, nh = 0.0.0.0, mt = 100
IP4.DNS[1]: 8.8.8.8
IP6.ADDRESS[1]: fe80::2e8a:2a2:9c75:15b9/64
IP6.GATEWAY: --
IP6.ROUTE[1]: dst = fe80::/64, nh = ::, mt = 100
Подробные настройки соединения можно посмотреть командой nmcli device show "Проводное соединение 1". Как вы можете заметить, у соединения настроек значительно больше, чем у устройства.
localadmin@astra:~$ nmcli connection show "Проводное соединение 1"
connection.id: Проводное соединение 1
connection.uuid: 26c78985-a471-3663-98bb-9afbf978d59c
connection.stable-id: --
connection.type: 802-3-ethernet
connection.interface-name: --
connection.autoconnect: да
connection.autoconnect-priority: -999
connection.autoconnect-retries: -1 (default)
...
Добавим сетевое соединение командой nmcli connection add type ethernet ifname eth1, где type указывает тип соединения ethernet, а имя ifname задает имя интерфейса.
localadmin@astra:~$ sudo nmcli connection add type ethernet ifname eth1
Соединение «ethernet-eth1» (4b3a041f-027d-4fae-903d-d1d953f268a5) добавлено.
localadmin@astra:~$ nmcli connection show
NAME UUID TYPE DEVICE
Проводное соединение 1 26c78985-a471-3663-98bb-9afbf978d59c ethernet eth0
ethernet-eth1 4b3a041f-027d-4fae-903d-d1d953f268a5 ethernet --
Задать значение IP-адреса можно командой nmcli connection modify ethernet-eth1 ipv4.address 192.168.0.2/24.
localadmin@astra:~$ nmcli connection modify ethernet-eth1 ipv4.address 192.168.0.2/24
Изменить способ назначения IP-адреса «вручную» можно командой nmcli connection modify ethernet-eth1 ipv4.method manual.
localadmin@astra:~$ nmcli connection modify ethernet-eth1 ipv4.method manual
Чтобы вернуть автоматическое назначение IP-адреса через DHCP, необходимо выполнить команду nmcli connection modify ethernet-eth1 ipv4.method auto
localadmin@astra:~$ nmcli connection modify ethernet-eth1 ipv4.method auto
Для того чтобы изменения настроек вступили в силу, нужно перезапустить соединение.
localadmin@astra:~$ nmcli dev reapply eth0
Соединение снова применено к устройству «eth0».
Можно также выключить и включить соединение командой
nmcli connection down "Проводное соединение 1" && nmcli connection up "Проводное соединение 1"
localadmin@astra:~$ nmcli connection down "Проводное соединение 1" && nmcli connection up "Проводное соединение 1"
Соединение «Проводное соединение 1» успешно отключено (активный адрес D-Bus: /org/freedesktop/NetworkManager/ActiveConnection/1)
Соединение успешно активировано (адрес действующего D-Bus: /org/freedesktop/NetworkManager /ActiveConnection/2)
Утилита Nmtui
Псевдографическая утилита nmtui (англ. Network Manager Text User Interface) будет полезна при настройке соединения на сервере или на рабочей станции в режиме командной строки. Для запуска наберите в консоли команду nmtui.
рис. 132 Начало работы с утилитой nmtui
Выберем пункт .
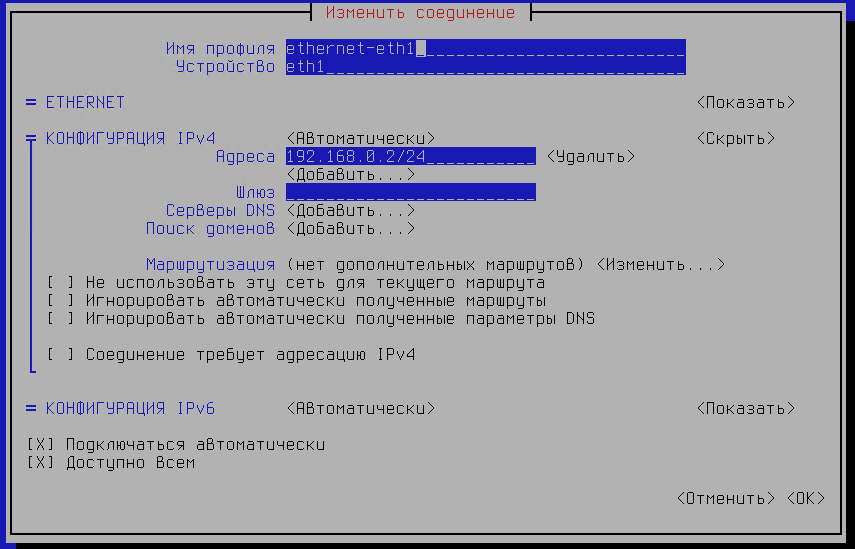
рис. 133 Настройки соединения
Изменим IP-адрес на 192.168.0.3/24, добавим шлюз по умолчанию 192.168.0.1 и DNS-сервер Яндекса 77.88.8.8.
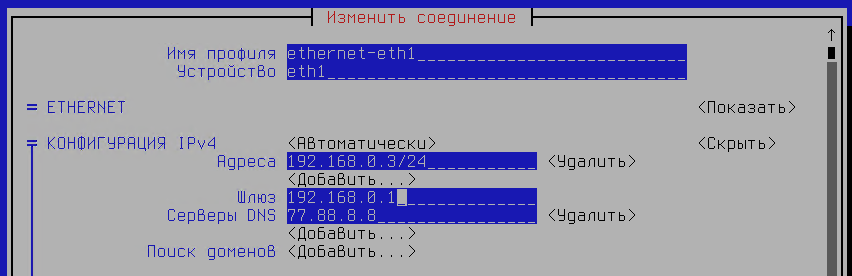
рис. 134 Настройки соединения
Сохраним настройки и завершим работу с утилитой. Убедимся, что настройки были сохранены.
localadmin@astra:~$ nmcli connection show ethernet-eth1 | grep ipv4
ipv4.method: auto
ipv4.dns: 77.88.8.8
ipv4.dns-search: --
ipv4.dns-options: --
ipv4.dns-priority: 0
ipv4.addresses: 192.168.0.3/24
ipv4.gateway: 192.168.0.1
ipv4.routes: --
ipv4.route-metric: -1
ipv4.route-table: 0 (unspec)
ipv4.routing-rules: --
ipv4.ignore-auto-routes: нет
ipv4.ignore-auto-dns: нет
ipv4.dhcp-client-id: --
ipv4.dhcp-iaid: --
ipv4.dhcp-timeout: 0 (default)
ipv4.dhcp-send-hostname: да
ipv4.dhcp-hostname: --
ipv4.dhcp-fqdn: --
ipv4.dhcp-hostname-flags: 0x0 (none)
ipv4.never-default: нет
ipv4.may-fail: да
ipv4.dad-timeout: -1 (default)
ipv4.dhcp-vendor-class-identifier: --
ipv4.dhcp-reject-servers: --
Графический интерфейс nm-connection-editor
Запустить графический интерфейс для редактирования настроек соединений можно из консоли командой nm-connection-editor, через меню или контекстное меню апплета в области уведомлений.
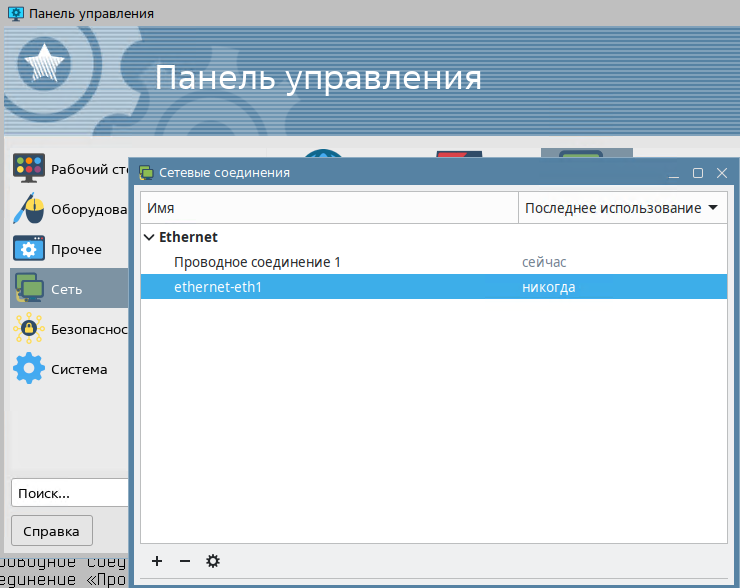
рис. 135 Утилита «Сетевые соединения»
Утилита имеет интуитивно понятный интерфейс. Представлен список сетевых соединений, их статус и кнопки управления , и .
Дважды кликнем по соединению . Перед нами появится окно «Изменение Проводное соединение 1», в котором есть несколько вкладок.
Вкладка Основное – общая настройка всех типов подключений и их приоритетов.
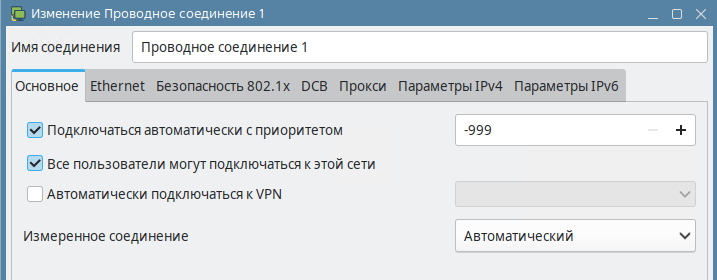
рис. 136 Основные настройки проводного соединения
Вкладка Ethernet (название зависит от типа подключения) — доступны параметры MAC-адрес, MTU и другие. Без необходимости их лучше не менять и использовать значения по умолчанию.
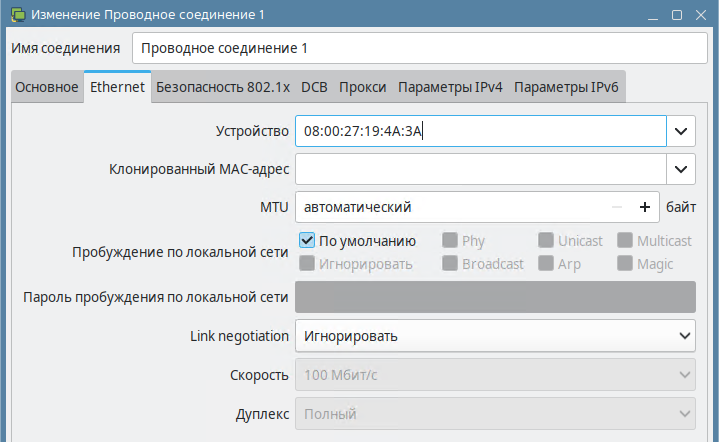
рис. 137 Настройки Ethernet
Вкладка Безопасность 802.1x – подключение к сети с использованием сервера аутентификации.
рис. 138 Настройки безопасности
Вкладка DCB – подключение к сети хранения данных по протоколу Datacenter Bridging.
рис. 139 Настройки DCB
Вкладка Прокси – настройка подключения через прокси-сервер.
рис. 140 Настройки прокси
Вкладка Параметры IPv4 – выбор метода установки параметров протокола IPv4 и их установка. Доступные для изменения параметры меняются в зависимости от выбранного метода. На этой вкладке можно задавать IP-адреса сетевого интерфейса, маски подсетей, серверы DNS, поисковый домен и другое.
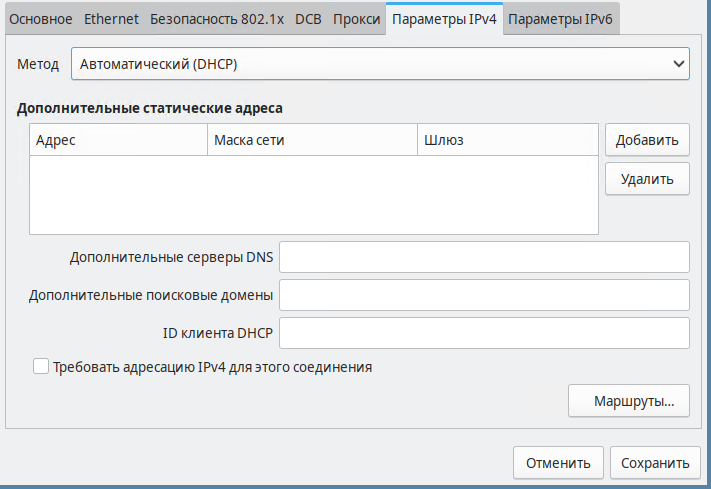
рис. 141 Настройка IPv4
По нажатию на кнопку «Маршруты» открывает окно, в котором доступно создание и редактирование статических маршрутов для этого соединения, что особенно актуально для всякого рода VPN-соединений.
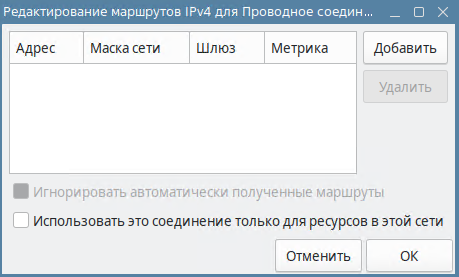
рис. 142 Настройка маршрутов
Внимание
При изменении DNS-серверов через NetworkManager, служба вносит изменения в файл /etc/resolv.conf, перетирая все его содержимое.
Вкладка Параметры IPv4 – выбор метода и параметров для протокола IPv6.
рис. 143 Настройка IPv6
Чтобы открыть окно «Сведения о текущем соединении», выберите соответствующий пункт в контекстном меню апплета, иконка которого находится в трее в правом нижнем углу экрана.
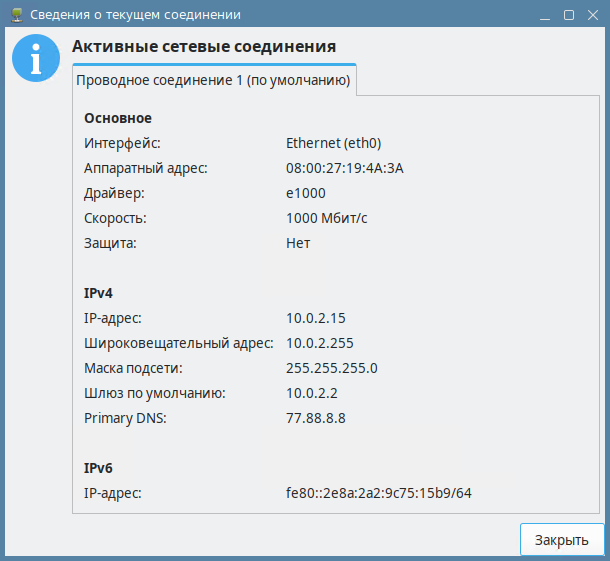
рис. 144 Просмотр сведений о соединении
Постоянное изменение настроек с помощью systemd
В systemd есть служба systemd-networkd, с помощью которой можно вносить постоянные настройки конфигурации сети. Файлы настроек этой службы находятся в каталоге /etc/systemd/network.
Служба считается преемницей ifupdown и подходит для настройки как простых подключений, так и сложных конфигураций. Она обладает рядом преимуществ, например, поддерживает новые сетевые функции и не задерживает загрузку системы для проверки сетевых интерфейсов. Однако, несмотря на это, в простых сценариях настройки сети консервативный мир Linux продолжает активно использовать более простую службу networking.
В операционной системе Astra Linux служба systemd-networkd установлена, но по умолчанию деактивирована.
Физический уровень
На физическом уровне обработка входящих пакетов выполняется в следующем порядке:
Все начинается с поступления цифровых сигналов на сетевую карту, где они преобразуются в двоичный поток данных. По сигнатуре Ethernet-кадра и его заголовку сетевая карта вычленяет кадр из потока.
Сетевая карта проверяет контрольную сумму Ethernet-кадра и MAC-адрес устройства, которому он адресован. Если проверки пройдены успешно, то корректный кадр помещается в буфер сетевого устройства.
Далее с использованием технологии DMA (англ. direct memory access, прямой доступ к памяти) кадр копируется в кольцевой буфер ядра или так называемую очередь. Размер выделяемой памяти, как правило, определяется двумя параметрами: количеством буферов (задается через настройки сетевой карты) и размером MTU (англ. maximum transfer unit — максимальный размер передаваемого кадра).
Если обработка очереди находится в обычном режиме, то сетевая карта генерирует аппаратное прерывание IRQ (англ. Interrupt Request — запрос на прерывание), что вынуждает процессор переключиться на обработку новых данных. Если очередь переведена в режим опроса, то данные вычитываются процессором при следующем цикле обработки данных.
Вы можете изменить, например, MAC-адрес и значение MTU. Относительно MAC-адреса мы уже знаем, что это должно быть просто уникальное значение в пределах сети, а в части MTU обратим ваше внимание на одну довольно сложную проблему.
Если в вашей сети пинги и трассировки проходят «на ура», а сайты не загружаются, то можем вас поздравить, вы столкнулись с так называемой черной дырой, которая ни разу не сверхмассивная звезда в космосе, а нарушение работы механизма согласования значения MTU.
Следует понимать, что вы можете выставить значение MTU на конкретном компьютере, но приемник и передатчик в сети должны действовать согласованно, поэтому фактическое значение MTU обычно определяется автоматически в момент установления связи, и эта процедура называется MTU discovery.
Для согласования значения MTU используется протокол ICMP: передатчик отправляет приемнику Ethernet-кадр с битом DF (не фрагментировать) в IP-заголовке и ждет, пока какой-то из узлов на пути следования кадра не отбросит его и не вернет ICMP-сообщение с требованием выполнить фрагментацию. Получив такое сообщение, передатчик уменьшает MTU и повторяет процедуру, пока значение MTU не станет достаточно маленьким, чтобы кадр прошел весь путь без фрагментации.
Но механизм согласования MTU может сломаться, если в сети присутствуют черные дыры (Path MTU Discovery Black Hole) — это такие узлы, которые отбрасывают большие кадры, не отправляя никаких ICMP-сообщений. Некоторые реализации автоматического согласования MTU пытаются обойти эту проблему и, не получив ответа, делают предположение, что это из-за MTU, а не по причине перегрузки канала. Но если в вашем случае это не сработало, то следует попытаться подобрать допустимое значение MTU вручную.
Уровень очередей
Получение пакетов
Когда скорость сетевого трафика исчислялась килобайтами в секунду, механизм обычных прерываний эффективно справлялся со своей задачей. Но прогресс целенаправленно вел индустрию к мега- и гигабитам, поэтому одной из оптимизаций стала технология NAPI (англ. New API — новый API), идея которой состояла в том, чтобы отложить обработку входящих сообщений до тех пор, пока их не наберется достаточное количество, чтобы сэкономить ресурсы на ненужных переключениях.
В технологии NAPI сохраняется баланс между двумя подходами: по умолчанию используется режим, управляемый прерываниями, а если скорость входящих пакетов превышает определенный порог, то сетевая карта переключается на режим опросов, и ядро начинает периодически обрабатывать входящие пакеты большими пачками, сокращая накладные расходы на прерывания, см. рис. 28. Когда нагрузка возвращается в норму, сетевая карта опять возвращается в режим прерываний, чтобы обеспечить более высокую скорость реакции.
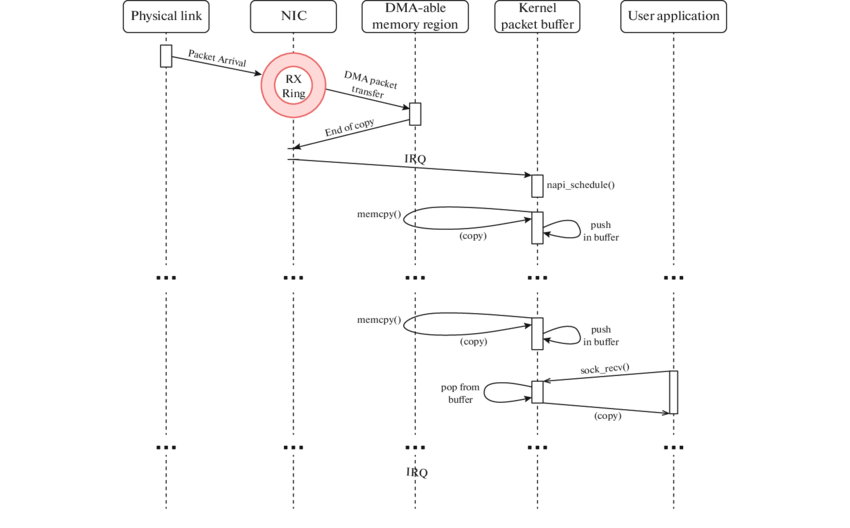
рис. 145 Схема обработки пакетов NAPI
При использовании кольцевого буфера новые кадры не отклоняются, а замещают собой старые. При необходимости приложения запросят повторную отправку потерянных кадров. Для оптимизации потребления ресурсов и ускорения обработки применяются и другие технологии:
Создание нескольких очередей, обрабатываемых на разных процессорах для распределения нагрузки (англ. Receive Packet Steering, RPS — распределение принимаемых пакетов).
Распределение обработки пакетов между очередями RPS для повышения частоты попадания в кэш ЦПУ (англ. Receive Flow Steering, RFS — распределение принимаемых потоков).
Направление пакетов в очередь, закрепленную за ядром ЦПУ, которое обрабатывает данные из этого потока (англ. Accelerated Receive Flow Steering, aRFS — ускоренное распределение принимаемых потоков).
На уровне очередей вы можете изменить длину очереди, включить/отключить использование оптимизаций RPS, RFS, aRFS.
Передача пакетов
При передаче пакетов каждый пакет обрабатывается процессором отдельно:
После того как данные были упакованы в IP-пакет, в очередь помещается указатель на этот пакет. В случае, если очередь переполнена, пакеты отбрасываются.
Драйверу сетевой карты сообщается, что пакеты готовы для отправки.
Сетевая карта отправляет пакет или группу пакетов и сообщает об этом системе через генерацию прерывания.
Уровень протоколов
На уровне протоколов выполняется сборка фрагментированных IP и TCP-пакетов и проверка их целостности. Входящие пакеты проходят по сетевому стеку вверх, пока данные не достигнут буфера сокета, чтобы стать доступными пользовательскому приложению, а исходящие данные совершают тот же путь только в обратном направлении.
Статистику по работе протоколов можно получить из файлов /proc/net/netstat, /proc/net/tcp, /proc/net/udp и др., но проще будет воспользоваться командой netstat -s, которая предоставит подробную информацию по каждому из параметров.
localadmin@astra:~$ netstat -s
Ip:
Forwarding: 2
528616 total packets received
0 forwarded
0 incoming packets discarded
528529 incoming packets delivered
330271 requests sent out
170 outgoing packets dropped
37 dropped because of missing route
Icmp:
1007 ICMP messages received
0 input ICMP message failed
ICMP input histogram:
Но самое интересное происходит, конечно, в части обработки пакетов правилами маршрутизации и фильтрации подсистемы Netfilter. Чтобы описать этот механизм в полном объеме, потребуется увеличить объем данного модуля в несколько раз, поэтому мы обозначим только общие моменты, которые помогут сориентироваться и задать общее направление, если эта тема вас заинтересует.
Для эффективной работы с правилами Netfilter вы должны четко понимать диаграмму движения пакетов, см. рис. 146.
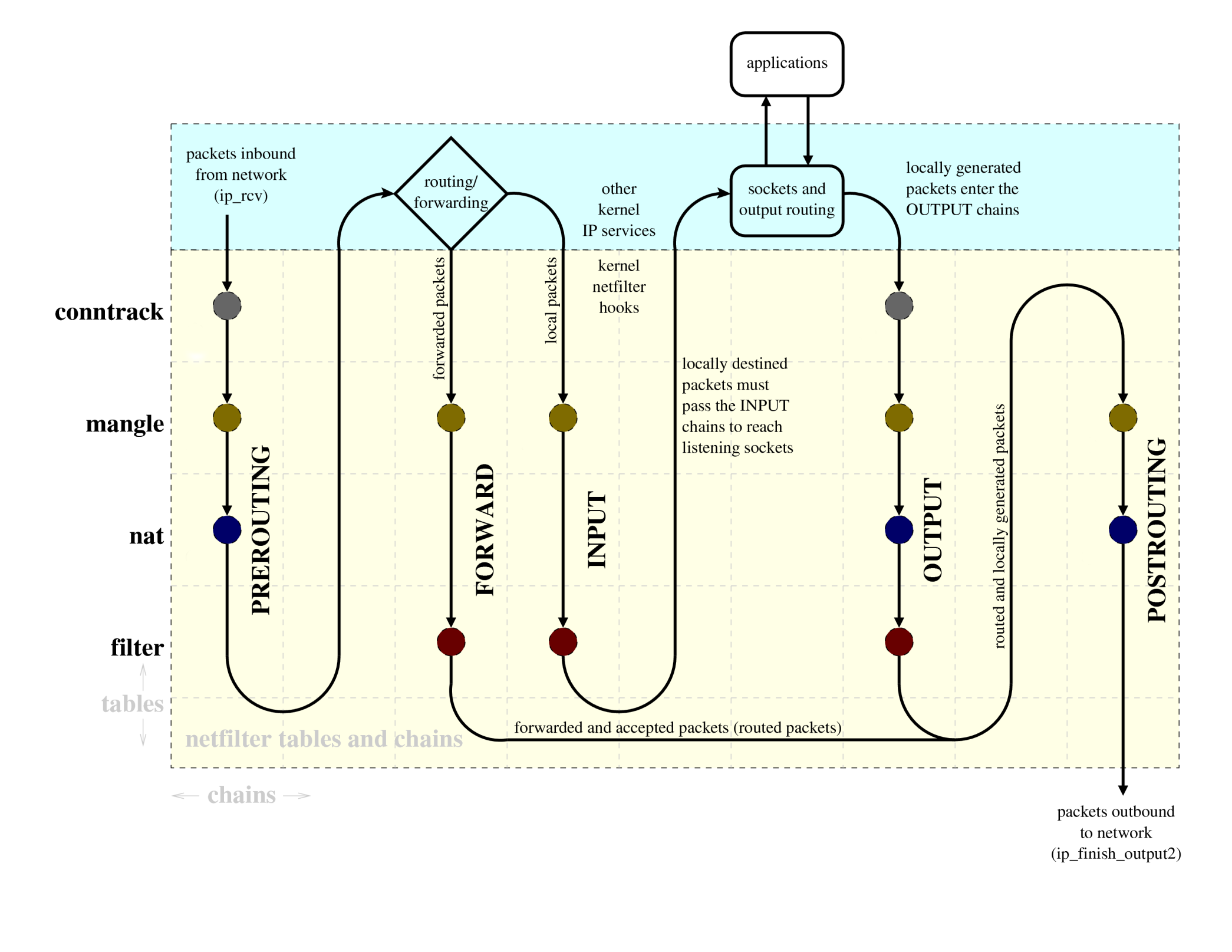
рис. 146 Диаграмма потока пакетов Netfilter
Работа межсетевого экрана определяется правилами, каждое из которых состоит из критерия и действия. Правила объединяются в три основные цепочки:
INPUT – входящие пакеты, которые были направленные одному из сетевых приложений, работающих на компьютере.
OUTPUT – исходящие пакеты, которые были созданы одним из сетевых приложений, работающих на компьютере, для другого узла сети.
FORWARD – входящие пакеты, которые компьютер должен передать дальше по сети, используя свои правила маршрутизации.
Обратите внимание, что по умолчанию пересылка пакетов отключена и для ее включения нужно выполнить команду:
$ echo 1 | sudo tee /proc/sys/net/ipv4/ip_forward
Дополнительно есть цепочки PREROUTING и POSTROUTING, через которые пакеты проходят до и после фильтрации соответственно.
Независимые цепочки объединяются в таблицы, каждая из которых решает определенную задачу: цепочки таблицы filter отвечают за фильтрацию, цепочки таблицы nat — за преобразование сетевых адресов (NAT).
Сильной стороной Netfilter является то, что он имеет модуль conntrack, который позволяет делать stateful-фильтрацию, т.е. при обработке отдельных пакетов использовать информацию не только из заголовков (источник, получатель) или содержимого пакетов, но и данные о соединении. При настройке правил вы можете использовать следующие состояния соединений:
NEW (новый) — означает, что пакет запрашивает установление нового соединения
ESTABLISHED (установлено) — означает, что пакет связан с существующим соединением, в рамках которого пакеты ходили в обоих направлениях.
RELATED (связанный) — означает, что пакет запрашивает установление нового подключения, но оно является частью существующего, как в случае с активными FTP-соединениями, когда подключение идёт к порту 20, а передача данных выполняется через динамический порт.
Механизм сокетов
При реализации сетевого стека в системе BSD (англ. Berkeley Software Distribution) разработчики создали новый вид программного интерфейса, который позволил связывать IP-адрес, тип транспортного протокола и номер порта, образуя таким образом «разъем для подключения».
Как физические разъемы делятся на вилки и розетки, так сокеты бывают клиентскими (исходящими) и серверными (входящими). Любое серверное приложение может функцией socket() создать «входящий» серверный сокет, связать его с неким IP-адресом и портом функцией bind(), после чего функцией listen() перейти в режим прослушивания для ожидания входящего соединения со стороны клиента, см. схему на рис. 147.
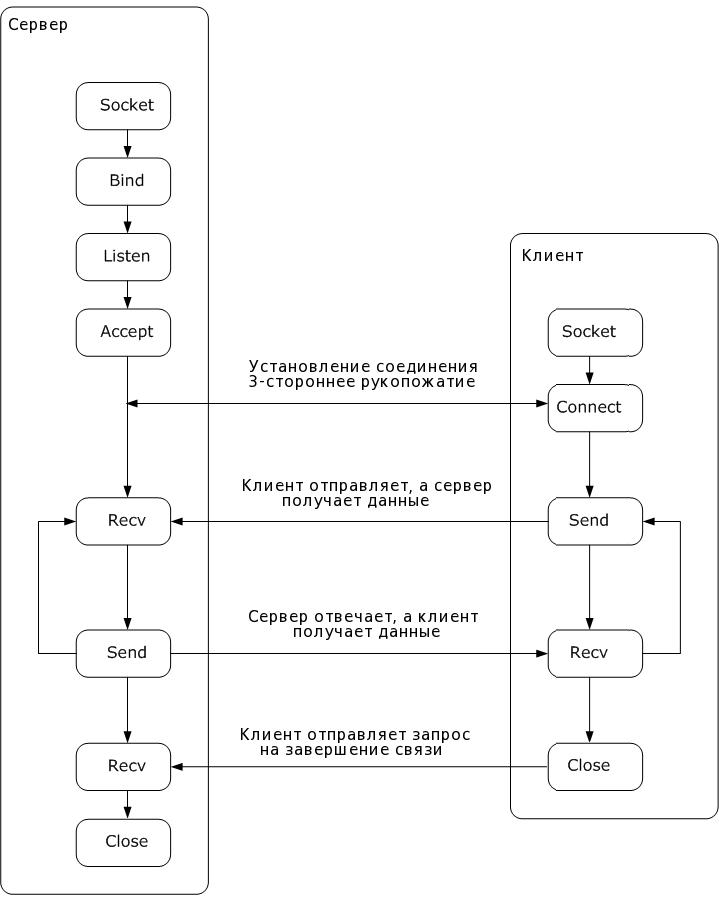
рис. 147 Схема установления связи и передачи данных между клиентом и сервером по сокету
Технология получила название «Сокеты Беркли» (англ. Berkley Sockets API) и вошла в стандарт POSIX.1, поэтому поддерживается сейчас всеми современными nix-подобными системами, и ее реализация есть даже в Windows (см. winsock).
Изначально сокеты задумывались как программный интерфейс для доступа к транспортному уровню TCP/IP, но несмотря на доминирующее положение этого стека, разработчики реализовали интерфейс по модульному принципу, что позволило обеспечить поддержку и альтернативных семейств протоколов, например, Appletalk и X25. Такое универсальное исполнение позволило реализовать в том числе поддержку «локального семейства сокетов», с помощью которого удалось избежать ненужных накладных расходов при сетевом взаимодействии приложений, установленных в рамках одной операционной системы.
Каждое семейство протоколов использует свое собственное «семейство адресов сокетов» (англ. socket address families), которое называется также «доменом» (только не путайте эти «домены адресов сокетов» с DNS-доменами или Kerberos-доменами). Семейство адресов обычного IPv4-сокета называется AF_INET, и адресом сокета является связка из IP-адреса, типа транспортного протокола и номера порта. Семейство локальных сокетов называется AF_LOCAL (синоним AF_UNIX), и адресом сокета является полное имя файла специального типа, например, уже известный нам /run/cups/cups.sock.
Снижение накладных расходов при использовании локальных сокетов достигается за счет того, что приложения общаются друг с другом напрямую в обход стека протоколов TCP/IP, то есть данные не разбиваются на TCP-сегменты с их последующей упаковкой в IP-пакеты и Ethernet-кадры. Файл сокета в этом случае является только конечной точкой для подключения, а обмен данными идет без обращения к диску, так как системные вызовы работают только с буферами ядра.
Сейчас в Linux доступно три типа unix-сокетов, которые отличаются контролем потока данных:
SOCK_STREAM — устанавливает соединение и обеспечивает возможность надежного двустороннего обмена потоками данных (
/run/systemd/journal/stdout,/run/dbus/system_bus_socket). В случае домена AF_INET этот тип используется для TCP.SOCK_DGRAM — обеспечивает передачу блоков информации фиксированного размера (датаграмм) без предварительного установления соединения (
/run/systemd/journal/dev-log,/run/systemd/notify). В случае домена AF_INET этот тип используется для UDP, но применительно к unix-сокетам передача датаграмм работает надежно, и их порядок не нарушается.SOCK_SEQPACKET — сочетает в себе свойства двух предыдущих типов, т.к. является потоко-ориентированным как SOCK_STREAM, но поддерживает установку границ записей, как SOCK_DGRAM. Доменом AF_INET не используется.
Приложения, установленные на один хост, взаимодействуют по unix-сокетам на десятки процентов быстрее, чем по TCP-сокетам с использованием IP-адресов локальной петли, поэтому, к примеру, все популярные SQL и NoSQL базы данных реализуют и такой способ взаимодействия тоже.
При необходимости отладки таких приложений для перехвата трафика вы можете временно переключить их с использования unix-сокета на обычный TCP/IP или воспользоваться приложениями двух типов:
Утилита
socat— позволяет заменить сокет на свой и сменить транспорт данных на домен AF_INET, где данные можно успешно сохранить (аналог MITM).Утилита
sockdump— использует механизм ядра BPF (Berkeley Packet Filters) и позволяет «слушать» сокет и сохранять данные по аналогии с сетевыми сокетами, см. https://github.com/mechpen/sockdump/tree/master.
Для примера работы с утилитой socat установим ее и напишем bash-скрипт:
$ sudo apt install socat tshark
$ nano ./dump-log_socat.sh
Вставим содержимое в скрипт dump-log_socat.sh:
#!/bin/bash
# Параметры
socket="/run/systemd/journal/dev-log"
dump="/tmp/dump_dev-log.pcap"
# Извлечение повторения
port=9876
source_socket="$(dirname "${socket}")/$(basename "${socket}").orig"
# Перемещение файлов сокета
mv "${socket}" "${source_socket}"
trap "{ rm '${socket}'; mv '${source_socket}' '${socket}'; }" EXIT
# Настройте канал через TCP, к которому мы можем подключиться
socat -t100 "TCP-LISTEN:${port},reuseaddr,fork" "UNIX-CONNECT:${source_socket}" &
socat -t100 "UNIX-LISTEN:${socket},mode=777,reuseaddr,fork" "TCP:localhost:${port}" &
# Регистрируем трафик
tshark -i lo -w "${dump}" -F pcapng "dst port ${port} or src port ${port}"
Теперь осталось запустить его с правами sudo и записать данные с сокета, а для прерывания записи нажмите Ctrl+C:
$ sudo bash ./dump-log_socat.sh
...
^C
$ sudo wireshark /tmp/dump_dev-log.pcap
Применение sockdump (нужен установленный bcc):
$ sudo apt install bison clang-format cmake dpkg-dev \
ethtool flex libbpf-dev libclang-cpp-dev libclang-dev \
libedit-dev libelf-dev libfl-dev libluajit-5.1-dev \
libzip-dev llvm-dev luajit python3-pyroute2
$ mkdir ~/sources; cd ~/sources
$ git clone https://github.com/iovisor/bcc; mkdir ./bcc/build; cd ./bcc/build
$ cmake .. && make –j "$(nproc)"
$ make install
$ cd ~/sources/; git clone https://github.com/mechpen/sockdump.git
$ cd sockdump
$ sudo ./sockdump.py /run/systemd/journal/dev-log --format pcap --output dump
...
^C
$ wireshark -X lua_script:wireshark/dummy.lua dump
При кажущейся сложности использование sockdump имеет несколько преимуществ: нет необходимости перемещать сокет (что может вызвать ошибки в других компонентах), имеется lua-скрипт, который позволяет декодировать бинарные данные в формат Wireshark.
Диагностика работы сети
Утилита ip
Команда ip neigh show выведет содержимое ARP-кэша:
localadmin@astra:~$ ip neigh show
10.0.2.2 dev eth0 lladdr 52:54:00:12:35:02 REACHABLE
Команда ip route show отобразит таблицу маршрутизации:
localadmin@astra:~$ ip route show
10.0.2.0/24 dev eth0 proto kernel scope link src 10.0.2.15
Для очистки ARP-кэша можно применить команду sudo ip neigh flush all:
localadmin@astra:~$ sudo ip neigh flush all
localadmin@astra:~$ ip neigh show
Утилита ping
Для проверки доступности узлов и времени прохождения пакетов можно воспользоваться командой:
localadmin@astra:~$ ping yandex.ru
PING yandex.ru (77.88.55.60) 56(84) bytes of data.
64 bytes from yandex.ru (77.88.55.60): icmp_seq=1 ttl=245 time=23.7 ms
64 bytes from yandex.ru (77.88.55.60): icmp_seq=2 ttl=245 time=25.5 ms
Если вы захотите повторить поведение одноименной утилиты из Windows, то укажите количество пакетов
ping -c 4 yandex.ru.
Проверим ARP-кэш и убедимся, что в нем появилась запись:
localadmin@astra:~$ ip neigh show
10.0.2.2 dev eth0 lladdr 52:54:00:12:35:02 STALE
Утилита traceroute
Команда traceroute применяется для проверки прохождения пакетов до узла назначения и до каждого из промежуточных узлов (маршрутизаторов), например:
localadmin@astra:~$ sudo traceroute yandex.ru -I
traceroute to yandex.ru (5.255.255.70), 30 hops max, 60 byte packets
1 10.0.2.2 (10.0.2.2) 0.241 ms 0.210 ms 0.175 ms
2 192.168.1.1 (192.168.1.1) 4.690 ms 4.652 ms 4.825 ms
...
6 pe03.KK12.Moscow.gldn.net (79.104.235.215) 17.615 ms 16.136 ms 16.276 ms
7 yandex-gw.moscow.gldn.net (195.239.153.234) 16.265 ms 16.291 ms 16.232 ms
8 * * *
9 yandex.ru (5.255.255.70) 26.937 ms 28.007 ms 27.981 ms
Примечание
Поведение tracert в Windows и traceroute в Linux отличается. По умолчанию traceroute использует протокол UDP, а не ICMP как tracert. Для использования протокола ICMP необходимо использовать traceroute с опцией -I (i заглавная), но в этом случае утилита требует прав суперпользователя.
Утилита netstat
Утилита netstat выводит список сетевых соединений, таблицы маршрутизации, статистику интерфейсов, NAT-соединения и членство в мультикаст-группах. Мы не будем подробно на ней останавливаться, так как рекомендуем использовать более современную утилиту ss, о которой будет рассказано ниже.
localadmin@astra:~$ netstat | head -10
Active Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
Active UNIX domain sockets (w/o servers)
Proto RefCnt Flags Type State I-Node Path
unix 2 [ ] DGRAM 27580 /run/user/107/systemd/notify
unix 2 [ ] DGRAM 28371 /run/user/1000/systemd/notify
unix 3 [ ] DGRAM CONNECTED 18032 /run/systemd/notify
unix 7 [ ] DGRAM CONNECTED 18044 /run/systemd/journal/socket
unix 15 [ ] DGRAM CONNECTED 18054 /run/systemd/journal/dev-log
unix 2 [ ] DGRAM CONNECTED 27519
Утилита ss
Утилита ss (англ. socket stat) – это инструмент командной строки, который отображает статистику сокетов системы Linux. Утилита может отображать статистику для сокетов TCP, UDP, DCCP, RAW, домена Unix и многого другого. Утилита позволяет отображать информацию, аналогичную netstat, при этом отображает больше, чем другие инструменты.
Опции утилиты:
Команда
ss -t— показывает активные TCP-соединения.Команда
ss -u— показывает активные UDP-соединения.Команда
ss -l— показывает только сокеты, ожидающие подключения.Команда
ss -p— PID и имя программы, которой принадлежит каждый из сокетов.Команда
ss -n— показывает числовые адреса, не пытаясь определить символьное имя узла, порт или имя пользователя.Команда
ss -tlp— показывает TCP-соединения и их ассоциированные процессы.Команда
ss -ulp— показывает UDP-соединения их ассоциированные процессы.Команда
ss -tulpn— показывает TCP и UDP-соединения и их ассоциированные процессы.Команда
ss -s— показывает общую статистику по типам сокетов.Команда
ss -a— показывает сокеты, ожидающие подключения и не ожидающие подключения.Команда
ss -xилиss -f unix— показывает unix-сокеты.
Показывает активные TCP и UDP соединения и их ассоциированные процессы:
localadmin@astra:~$ ss -tlp
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 128 0.0.0.0:sunrpc 0.0.0.0:*
LISTEN 0 128 127.0.0.1:ipp 0.0.0.0:*
LISTEN 0 128 [::]:sunrpc [::]:*
LISTEN 0 128 [::1]:ipp [::]:*
Показывает TCP и UDP-соединения и их ассоциированные процессы:
localadmin@astra:~$ ss -tulp
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
udp UNCONN 0 0 0.0.0.0:56863 0.0.0.0:*
udp UNCONN 0 0 0.0.0.0:sunrpc 0.0.0.0:*
udp UNCONN 0 0 0.0.0.0:mdns 0.0.0.0:*
udp UNCONN 0 0 [::]:33353 [::]:*
udp UNCONN 0 0 [::]:sunrpc [::]:*
udp UNCONN 0 0 *:xdmcp *:*
udp UNCONN 0 0 [::]:mdns [::]:*
tcp LISTEN 0 128 0.0.0.0:sunrpc 0.0.0.0:*
tcp LISTEN 0 128 127.0.0.1:ipp 0.0.0.0:*
tcp LISTEN 0 128 [::]:sunrpc [::]:*
tcp LISTEN 0 128 [::1]:ipp [::]:*
Показывает TCP и UDP-соединения и их ассоциированные процессы, не пытаясь определить символьное имя узла, порт или имя пользователя:
localadmin@astra:~$ ss -tulpn
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
udp UNCONN 0 0 0.0.0.0:56863 0.0.0.0:*
udp UNCONN 0 0 0.0.0.0:111 0.0.0.0:*
udp UNCONN 0 0 0.0.0.0:5353 0.0.0.0:*
udp UNCONN 0 0 [::]:33353 [::]:*
udp UNCONN 0 0 [::]:111 [::]:*
udp UNCONN 0 0 *:177 *:*
udp UNCONN 0 0 [::]:5353 [::]:*
tcp LISTEN 0 128 0.0.0.0:111 0.0.0.0:*
tcp LISTEN 0 128 127.0.0.1:631 0.0.0.0:*
tcp LISTEN 0 128 [::]:111 [::]:*
tcp LISTEN 0 128 [::1]:631 [::]:*
Показывает общую статистику по типам сокетов:
localadmin@astra:~$ ss -s
Total: 420
TCP: 6 (estab 0, closed 2, orphaned 0, timewait 0)
Transport Total IP IPv6
RAW 0 0 0
UDP 7 3 4
TCP 4 2 2
INET 11 5 6
FRAG 0 0 0
Практика и тестирование
Заключение
В этом модуле мы разобрали, как работает сетевой стек TCP/IP, и научились его настраивать в Astra Linux с помощью нескольких инструментов. Как мы уже отмечали, навыки настройки сети крайне важны в домене, поэтому настоятельно рекомендуем несколько раз вернуться к материалам этого модуля и обязательно выполнить предлагаемые практические задания.
В следующем модуле мы познакомимся с системами журналирования в Astra Linux, затронем вопросы анализа производительности системы и сбора отладочной информации. Разберем виды нештатных ситуаций, которые могут возникнуть на ранних и поздних этапах загрузки ОС и способы их устранения.
Дополнительные источники информации
Официальное руководство Cisco по подготовке к сертификационным экзаменам 100-101 или 100-105, Уэнделл Одом (ISBN 978-5-8459-1807-9)
Обратная связь
Если остались вопросы, то их всегда можно задать в специальной теме.